Development record of Korean reasoning model Ko-R1-3 #2 (2025.07.23)
Date
Jul 24, 2025
Category
Research
Development of Ko-R1-3 #2
Through our 'Development record of Korean roeasoning model, Ko-R1-3 #1 (2025.07.11)', we examined various aspects of model training. In the meantime, our team, in collaboration with KISTI and ORACLE, carried out approximately 50 training runs across two H200 and two H100 nodes. Within just one week, we conducted large-scale experiments consuming more than 2,000 H200-hours of compute resources.
At present, we have collected over 10 million samples for Korean post-training. However, training on the full dataset for five epochs would far exceed the thousands of compute hours we have already used and would surpass our resource budget. As a result, we were compelled to identify the optimal composition of post-training data — determining which samples to retain or discard and which data types to emphasize to maximize model performance. In the following sections, we share the key insights gained from this process.
Dataset Composition
The dataset used for experiments and model training consists of seven distinct categories:
OpenThought3: We translated the OpenThought3 prompts into Korean using the gemini-2.5-flash-lite-preview-06-17 model. During this process, samples with significant changes in length were filtered out to maintain alignment quality.
rStar-Coder: The same translation and filtering procedure applied to OpenThought3 was also used to construct the rStar-Coder dataset.
Web-Daily/Code/Science/Medical: This dataset comprises Korean instruction samples collected from the web, tagged by content type. We removed samples containing images, those that were unreasonably short or long, and samples with unclear intent. While the Web-Daily subset includes some noisy or potentially unsafe prompts, the Code, Science, and Medical subsets are comparatively cleaner and often include domain-specific terminology.
MCQA-Augmented: Starting from the KMMLU-Train subset, we incorporated data augmented with varied answer styles, such as responses formatted as "Answer: N" or "\boxed{N}". Additional augmentation was conducted using BM25 retrieval to gather semantically similar questions, resulting in a more diverse set of multiple-choice QA formats.
All dataset construction and augmentation procedures were performed using Qwen3-32B. The overall pipeline required approximately 4,000 H100 hours. (At the time of writing, data generation is still ongoing.)
Evaluation Setup
To mitigate benchmark overfitting of the model, we evaluated existing Korean benchmarks by partitioning them into distinct validation and test sets as follows.
Category | Validation | Test |
|---|---|---|
General | KMMLU-Redux | KMMLU-Pro, GPQA |
Reasoning | MCLM-Ko | HRM8K, LiveCodeBench |
Korean Knowledge | HAE-RAE Bench | CLicK, KoBALT |
Medical | ClinicalQA |
Inference Hyperparameters:
temperature=0.7,top_p=0.9,max_tokens=32768
Training Results
Ablation #1: Performance per category
As a first step, we analyzed the impact of each dataset—OpenThought3, the four web-derived datasets, and MCQA-Augmented—on model performance. To mitigate potential model-specific biases, we conducted experiments using two distinct models: Kanana-1.5-8B-Instruct and Gemma3-4B-Instruct. Additionally, to ensure that the models could generalize effectively to the MCQA format, a minimal amount of MCQA data was incorporated into the training corpus.
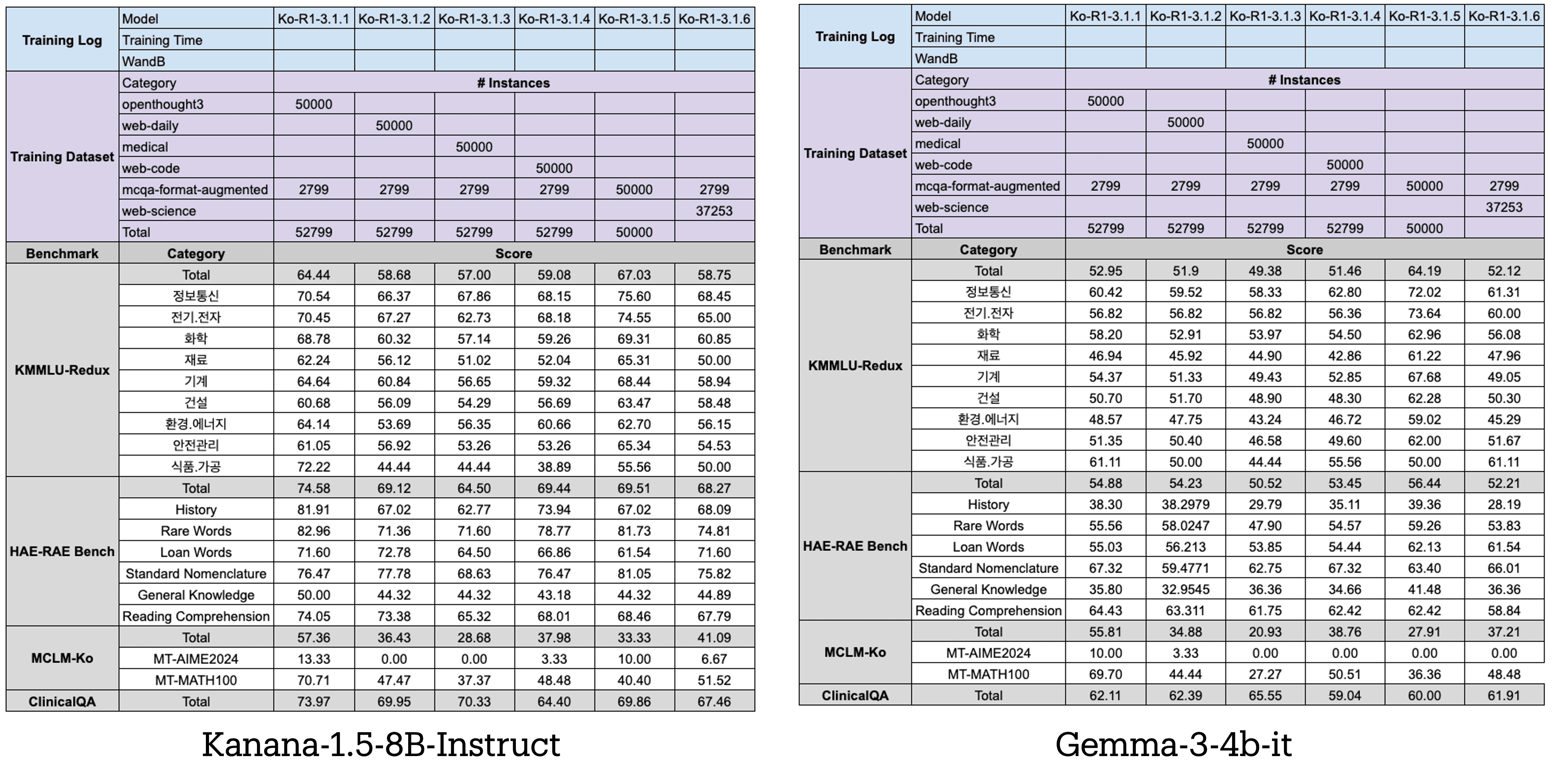
The results demonstrate that the OpenThought3 data leads to performance improvements across all benchmarks, including the knowledge-intensive HAE-RAE Bench. This indicates that the base model does not fully exploit its own parametric knowledge. Following this, notable gains are observed in the order of MCQA-Augmented, Web-Science, and Web-Code. Contrary to expectations, the inclusion of Web-Medical data had minimal impact on the ClinicalQA score. As a follow-up, we increased the size of the Web-Medical dataset to 100k examples to investigate whether scaling can unlock its hidden value.
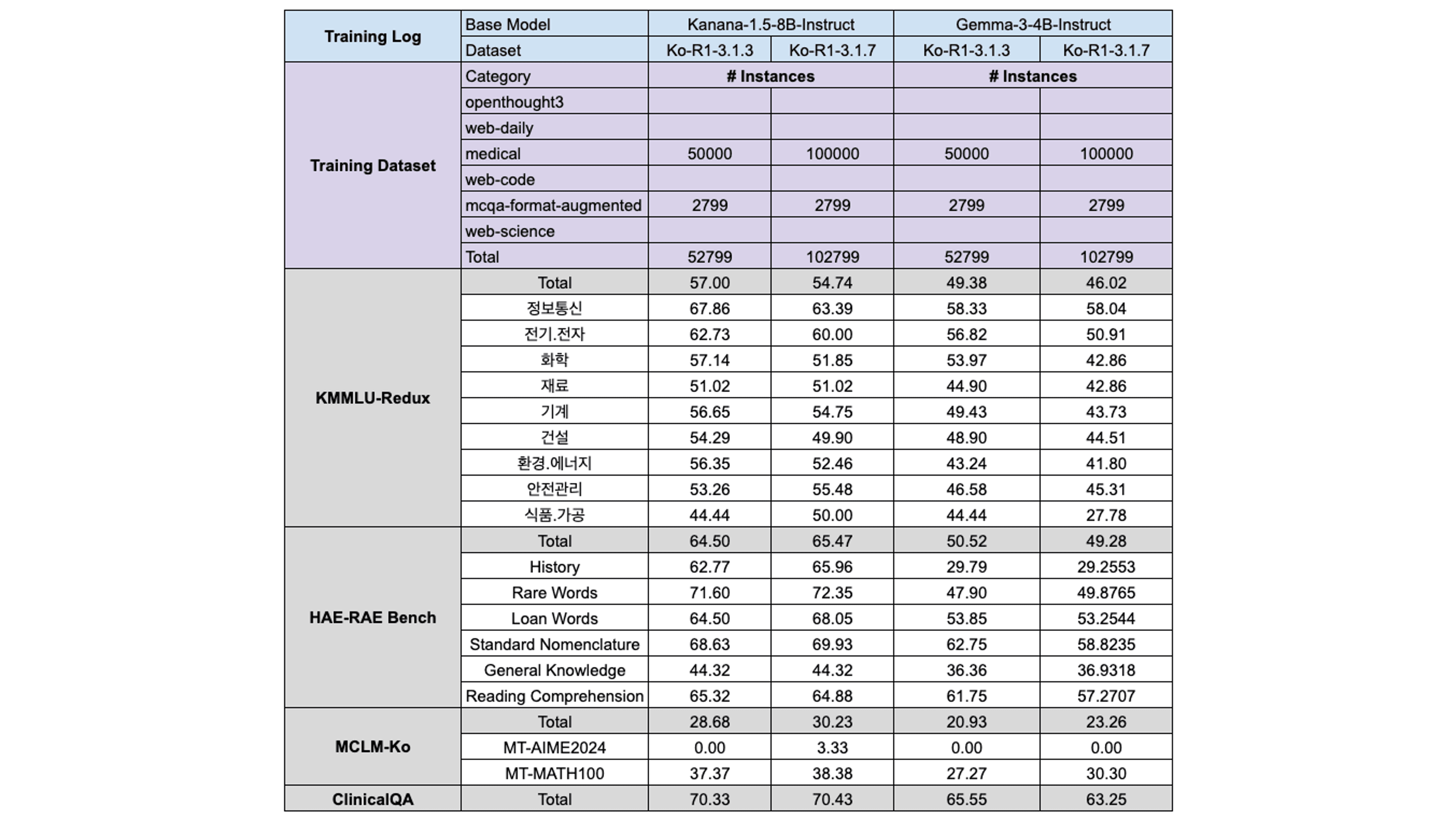
When scaling was applied to the Web-Medical dataset, it was observed that the performance either showed no significant improvement or, in some cases, even deteriorated across both models. Consequently, the dataset was excluded entirely from the final training phase.
Ablation #2: Cross-category benefits
The data not only contributes to performance improvements when used individually but also yields additional gains when combined with other datasets. Considering this aspect, we further analyzed the effects of data mixing on the collected datasets.
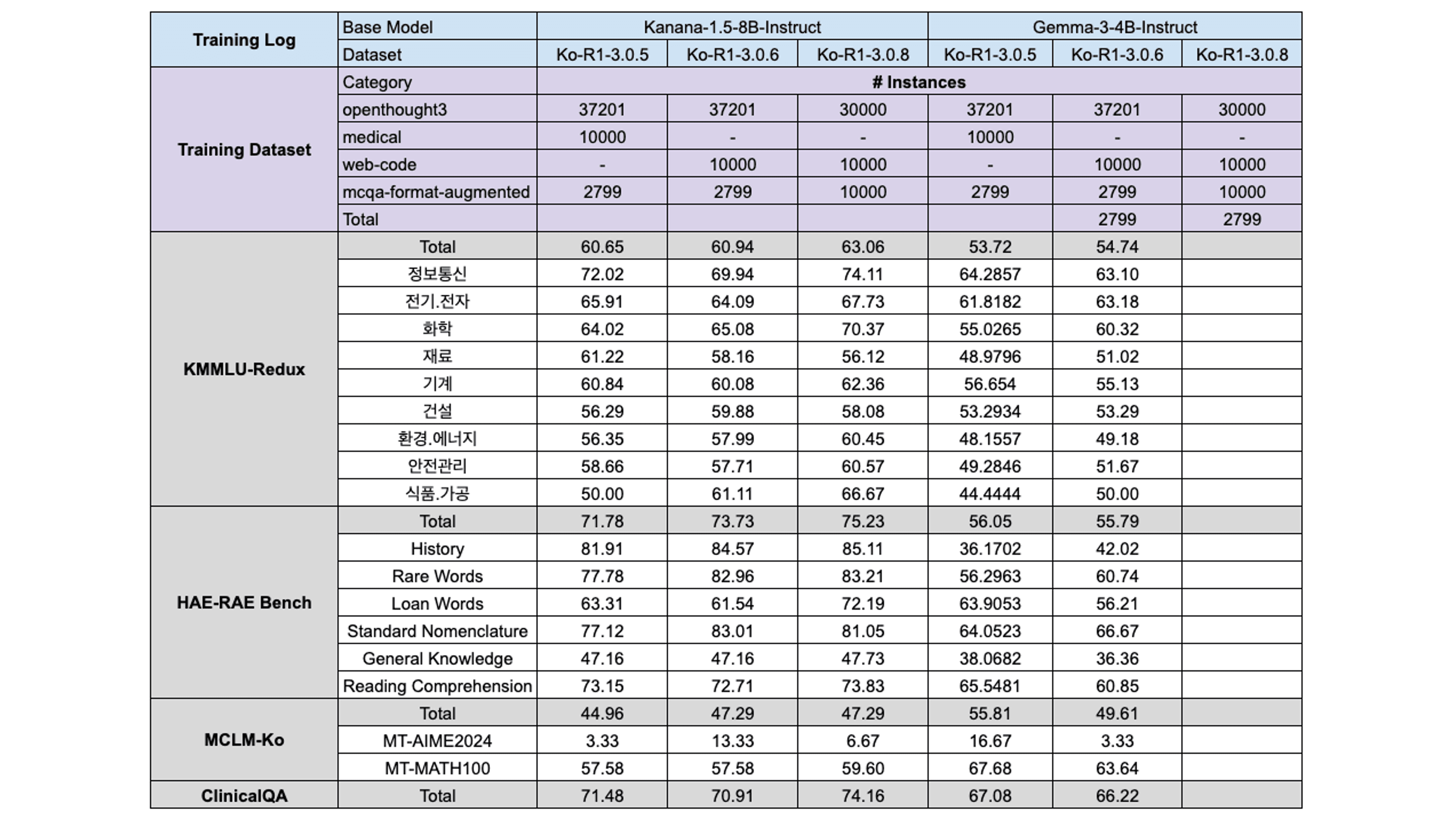
The comparison between Kanana models Ko-R1-3.0.5 and 3.0.6 further underscores the limited utility of the previously used Web-Medical data. In this training setup, replacing Web-Medical with Web-Code led to more substantial performance gains on both the HAE-RAE Bench and MCLM benchmarks. Moreover, we observed a synergistic effect between the Web-Code data and the MCLM benchmark, which motivated the inclusion of translated rStar-Coder data—a high-quality code dataset—into the training corpus. (However, the Gemma model did not benefit significantly from the code data.)
Ablation #3: To Augment or Not To Augment
Next, we investigated the extent to which the KMMLU-Train set can be augmented. In this process, we employed BM25 to retrieve semantically similar questions and then modified their answer choices to increase the number of options, thereby enhancing the diversity of the dataset.
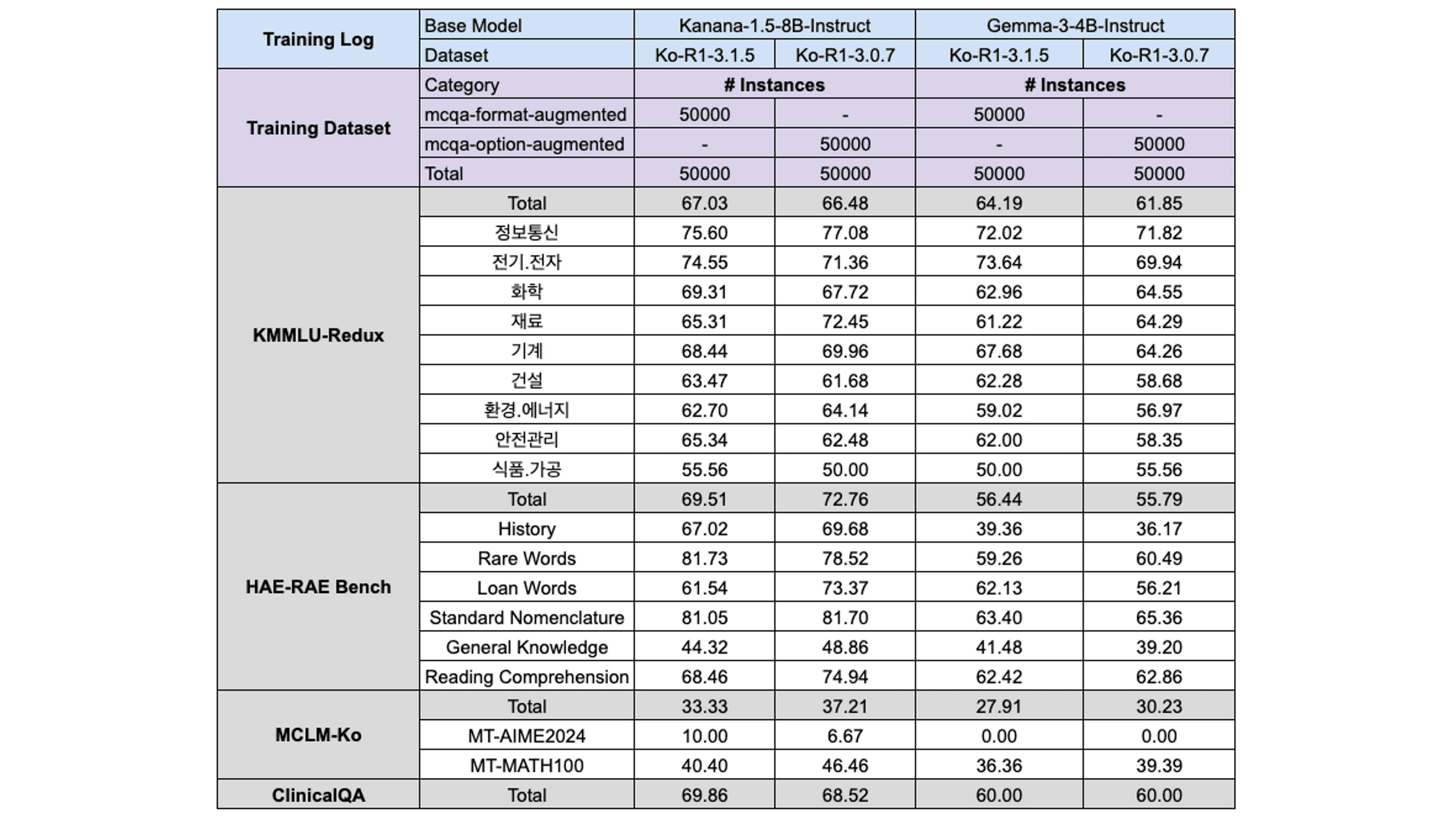
However, training the model on the augmented data led to degraded performance across most MCQA benchmarks. We hypothesize two primary reasons for this outcome:
The BM25-based augmentation of correct answer choices introduced noise that hindered effective learning.
Since most evaluation benchmarks consist of four options, augmenting the correct choices may have disrupted the intended task structure.
Therefore, in the final training phase, only a small portion of the augmented MCQA dataset was included to preserve diversity without compromising overall performance.
Ablation #4: Korean-English mix
For the final model training, we included English data to increase the overall data volume. To leverage English data without compromising performance on Korean, we conducted experiments with the following data ratio settings: 1:1 and 1:4 (Korean:English).
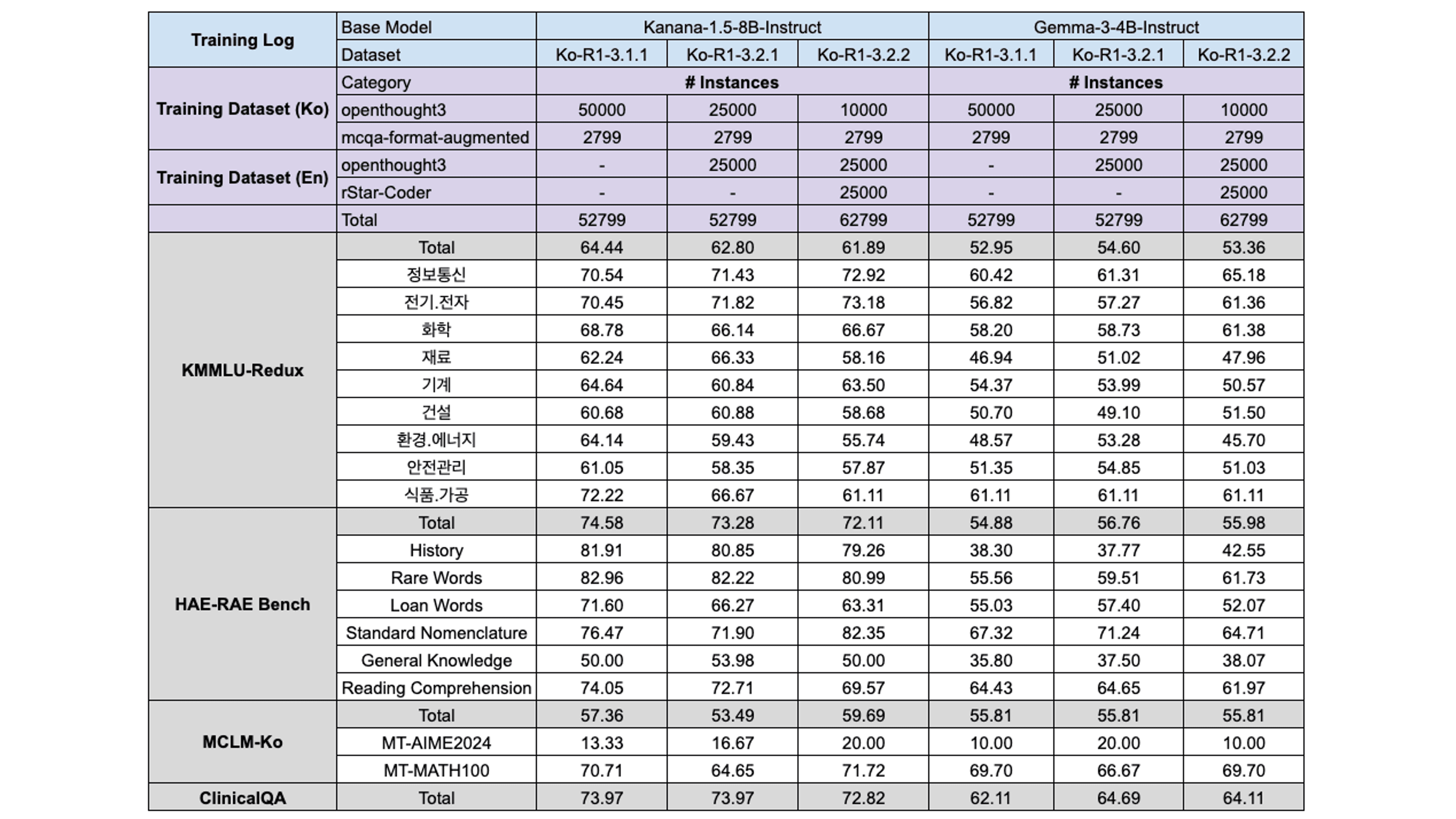
For the Kanana model, consistent with previous experiments, incorporating additional English data leads to decreased performance on KMMLU-Redux and HAE-RAE Bench, while the inclusion of rStar-Coder data improves mathematical reasoning capabilities. In contrast, the Gemma model demonstrates resilience to English data augmentation, exhibiting minimal performance degradation. This discrepancy suggests that Kanana is more sensitive to large-scale Korean reasoning data, whereas Gemma is capable of integrating English data without incurring significant penalties.
Extra Analysis
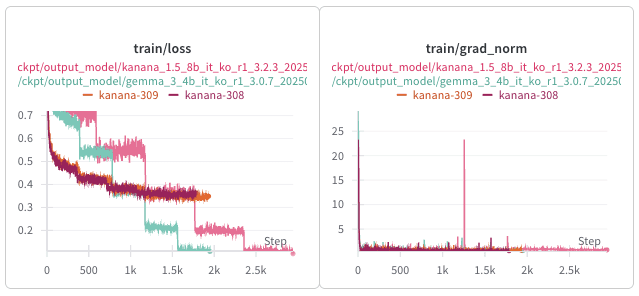
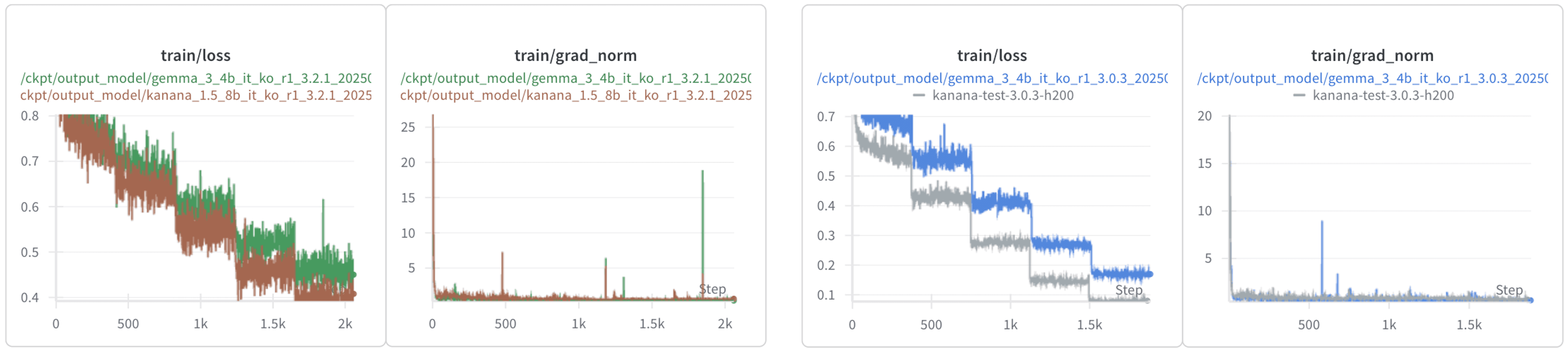
1. Loss Spikes & Grad-norm
Despite being trained on the same data, Gemma exhibited sharp fluctuations in grad-norm and occasional loss spikes. However, these phenomena did not have a significant impact on the final checkpoint.
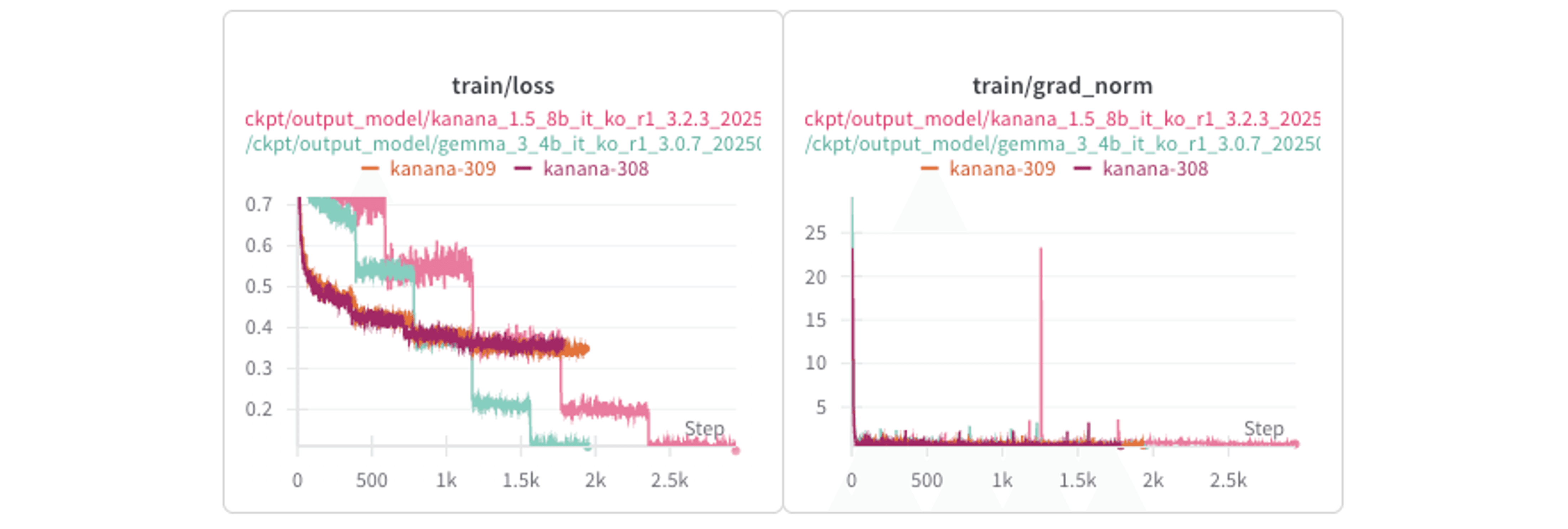
2. Loss Curves
In a single-GPU setting without the use of gradient checkpointing or FSDP, the loss curve exhibited relatively smaller fluctuations. In contrast, in a multi-GPU environment, the loss showed a more step-like drop at each epoch. However, this phenomenon did not have a significant impact on the final performance of the model.
References
📝 Original Post - Link
