The Road to Ko-R1-3: Early Insights and Discoveries in Korean AI Reasoning (2025.07.11)
Date
Jul 14, 2025
Category
Research
The Beginning of Ko-R1-3 Development
Two years ago, when Stanford's Alpaca introduced a new paradigm for open-source LLM development, HAE-RAE was formed with the mission to set the standard for Korean language models. With the goal of establishing a standard for evaluating Korean models, we have contributed to the Korean NLP research ecosystem over the past two years by releasing various benchmarks, including KMMLU, HAE-RAE Bench, and HRM8K.
Early this year, the emergence of DeepSeek-R1, with its powerful reasoning performance, inspired us to move beyond building benchmarks and dive into model development ourselves. Our first result, Ko-R1, showed impressive performance on mathematical reasoning problems. However, it also revealed clear limitations in certain areas, struggling to properly answer simple, everyday questions.
Building on this experience, OnelineAI, HAE-RAE, and KISTI have collaborated to overcome the limitations of Ko-R1 and have begun developing Ko-R1-3, a next-generation Korean reasoning model with the following strengths:
Powerful Performance: A model that demonstrates strong performance across a wide range of benchmarks, not just in reasoning ability.
Robustness in Everyday Questions: A model with excellent robustness in casual conversation, going beyond just knowledge-based or reasoning questions.
Flexible Reasoning Control: A model that allows users to flexibly switch between
thinkandnot_thinkmodes according to their preference.High Reliability: A model that ensures safety, making it trustworthy for anyone to use.
In this post, we will share the challenges we encountered during the initial development of Ko-R1-3 and the solutions we devised to overcome them.
Dataset Collection
Before training, our primary focus was on building a solid foundation to ensure the model could robustly handle not only reasoning tasks but also everyday questions. To achieve this, we collected approximately 7 million data points from various online communities and web pages over the past two months. This raw data then underwent post-processing, including deduplication and image removal. Subsequently, we used the Qwen3-32B model to generate an additional 2 million reasoning-focused data points to create the final training dataset.
Model Training & Trial and Error
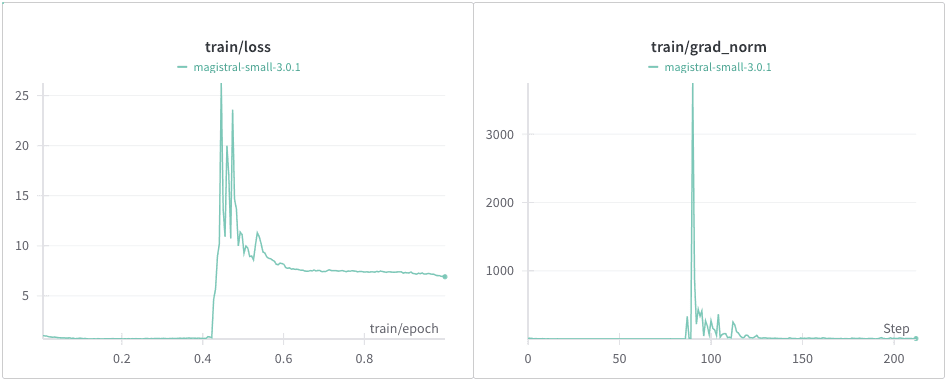
Loss Spikes
We discovered an anomaly immediately after starting to train the Magistral-24B model with 130,000 (130K) samples from the full dataset. As you can see in the graph below, the training loss spiked abnormally, which suggested a problem with our training data. Upon analyzing the data in the corresponding batches (89-91) to identify the cause, we found that the issue stemmed from the inclusion of English-only data, instead of our intended "English reasoning & Korean response" format.
To ensure training stability, we applied a filter to keep only the samples that meet the following criteria:
Each sample must contain only one
<think> ... </think>tag.The number of Korean tokens in the response generated after the
</think>tag.
Loss Drifts
Immediately after resolving the loss spike issue, we encountered an unexpected problem where the loss began to increase sharply. We identified the cause as the model being stuck in a local minimum and stabilized the loss curve by adjusting the hyperparameters as follows:
Decreased the learning rate
Increased the weight decay
Reduced the number of warm-up steps
Changed the optimizer (from 8-bit to AdamW)
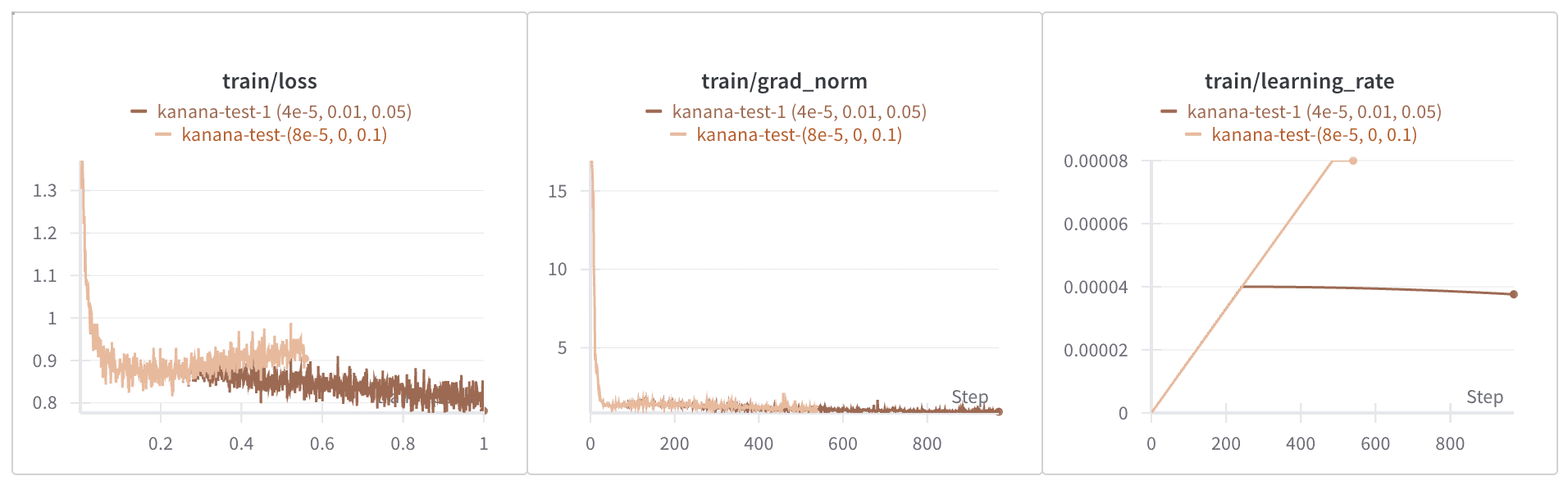
After stabilizing the dataset and hyperparameter settings, we switched the training model to Kanana-8B-Instruct. When we set a higher learning rate for the Kanana model, we observed the loss curve trending upwards again, so we proceeded to lower the learning rate once more.

Optimization of Dataset Composition
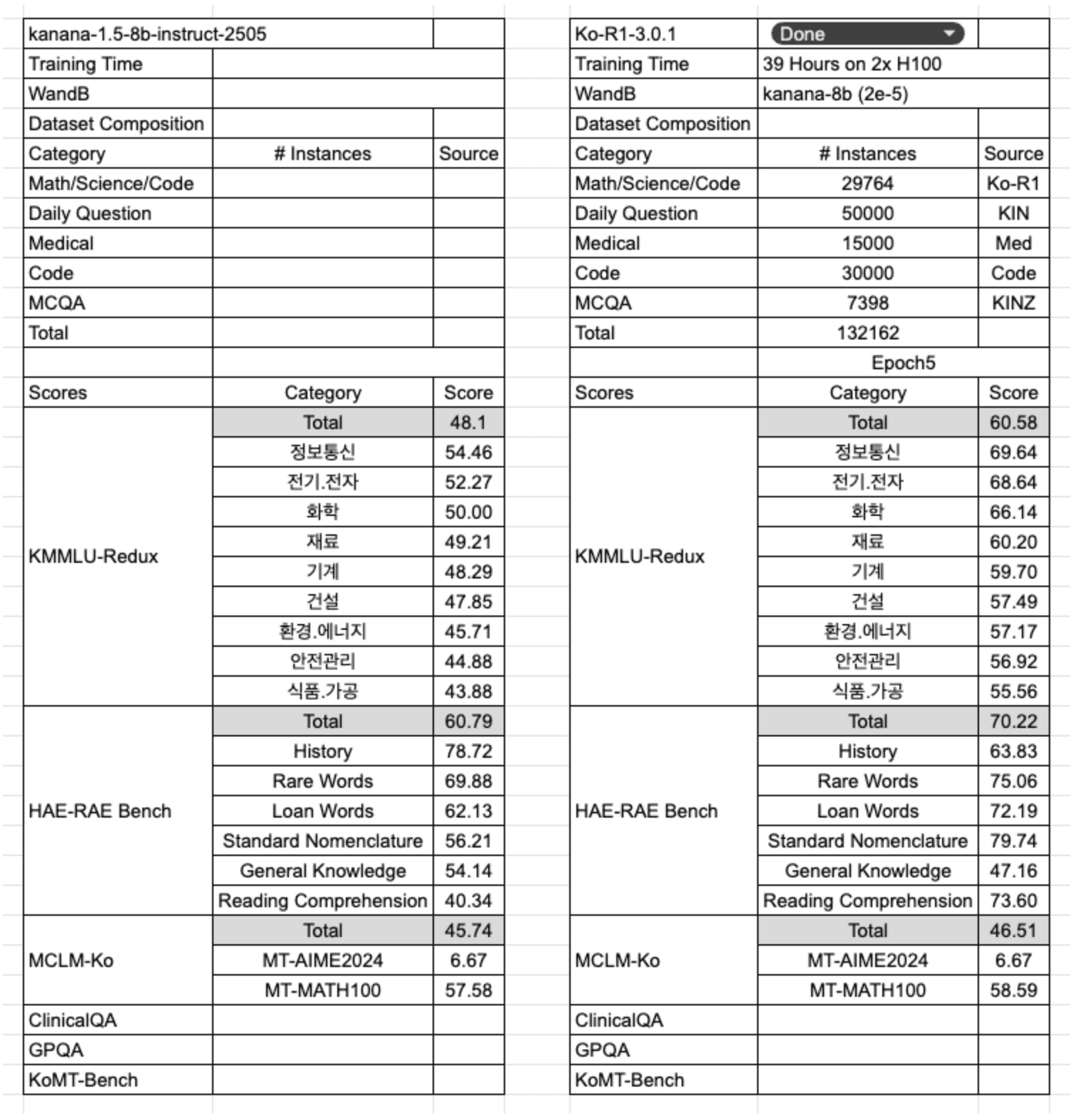
1st Run - Ko-R1-3.0.1
After an initial training run of 5 epochs on a sample dataset (represented by the purple curve in the graph), we saw performance improvements on the MCQA benchmarks (KMMLU-Redux, HAE-RAE Bench). However, there was no significant improvement on the MCLM-ko benchmarks (AIME2024, MATH). This was a concerning sign, as it indicated that the model's performance had stagnated on complex tasks like math, science, and coding—areas where it needs to demonstrate its core reasoning abilities.
2nd Run - Ko-R1-3.0.2
Following the first run, we adjusted the dataset composition for the next training phase. First, we replaced the existing math and science data from the Ko-R1 dataset with the higher-quality OpenThought3 dataset. During this process, we translated the OpenThought3 samples into Korean using the Gemini-2.0-Flash model and generated Korean responses with the Qwen3-32B model. Additionally, to investigate the impact of data formatting on model performance, we excluded the MCQA-style KINZ dataset from the training data.
The model's evaluation results aligned perfectly with our expectations. Performance improved on the MCLM-Ko benchmarks, while it tended to decrease on the KMMLU-Redux and HAE-RAE Bench. This experiment clearly confirmed two key findings:
The OpenThought dataset is crucial for enhancing the model's mathematical reasoning capabilities.
Training data in an MCQA format has a decisive impact on performance in benchmarks of the same format.
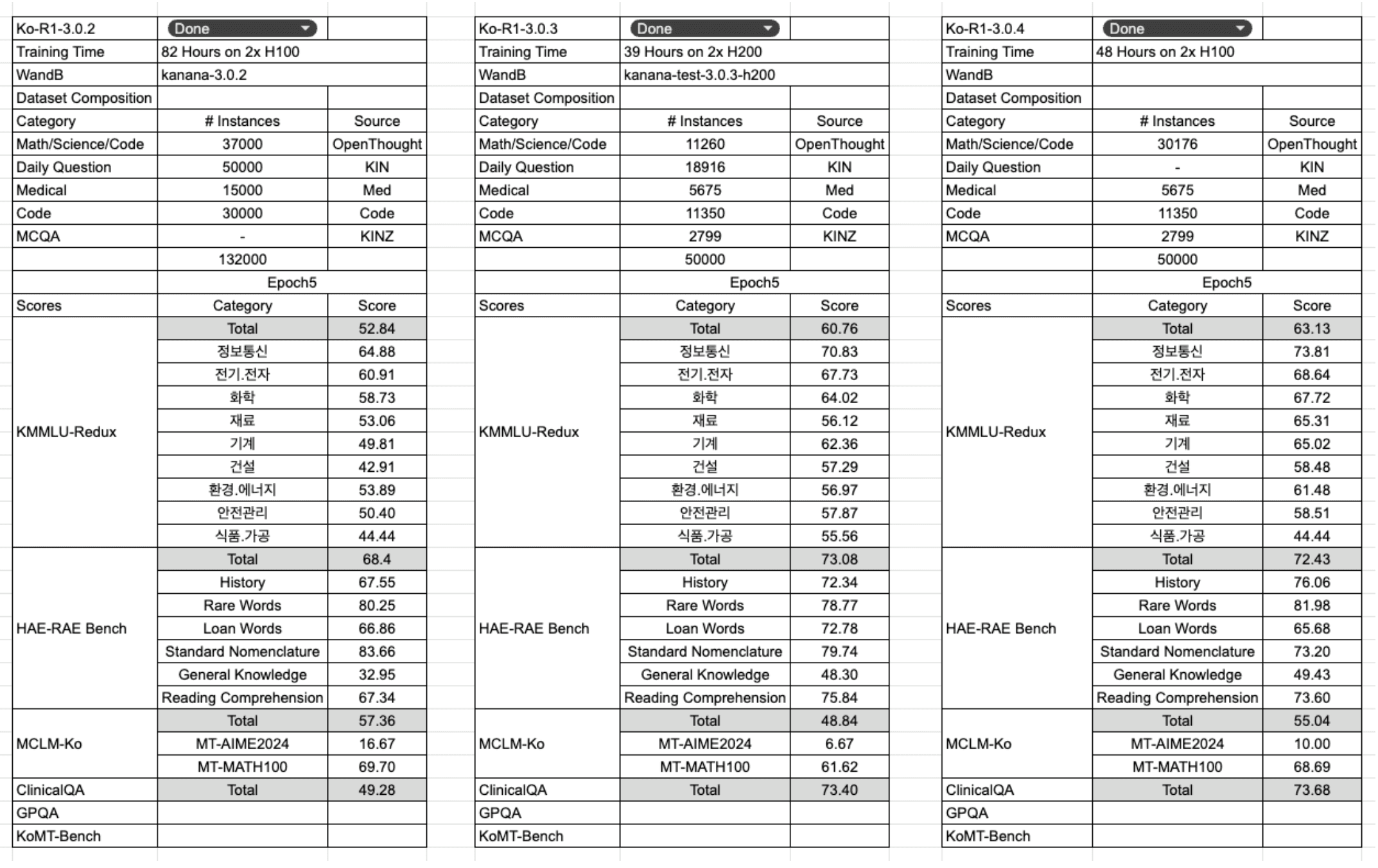
3rd Run - Ko-R1-3.0.3
After the second run, we tested training efficiency by sampling the dataset down to 50k samples (about 30% of its previous size) while maintaining the original category distribution. Interestingly, with just 2.7k MCQA samples, the model was able to restore its performance on the KMMLU-Redux and HAE-RAE Bench benchmarks to a level comparable to the previous run. However, performance improvement on the MCLM-ko benchmark was relatively slow, suggesting that further refinement was needed.
4th Run - Ko-R1-3.0.4
In the fourth run, we kept the dataset size at 50k samples but replaced the 'daily question' data with 'OpenThought' data. As a result, we were able to achieve performance nearly on par with the second run across most benchmarks, but at only half the training cost.
Takeaways & Future Plans
As we developed Ko-R1-3, three key insights emerged:
OpenThought Data Scales Beautifully: We saw a clear scaling effect with the OpenThought dataset. Simply put, the larger the dataset grew, the better the model performed, showing a direct, proportional benefit.
MCQA Data is Crucial for Top Scores: To excel on both general reasoning and multiple-choice benchmarks, we confirmed once again that having data in the MCQA format is a must.
'Daily-Question' Data Had Little Effect (For Now): On the other hand, we didn't see any significant score improvements on our current benchmarks from using the 'daily-question' data.
However, it's far too early to write off the 'daily-question' data. The issue might not be the data itself, but our tests; current benchmarks simply weren't built to measure the unique benefits this data offers. Going forward, we plan to design new tests to properly assess this capability and search for other scalable dataset combinations beyond just OpenThought.
References
📝 Original Post - Link
