Test-Time Scaling, 다국어 환경에서도 통할까?
날짜
2025. 5. 30.
카테고리
Research
"Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning" 논문을 기반으로 다국어 환경에서 LLM의 Test-Time Scaling의 효과에 대해 분석하는 내용을 다루고 있습니다. 해당 논문은 ACL 2025 Main Track에 게재되었습니다.
이 시리즈는 원라인에이아이에서 발표한 논문을 리뷰합니다. 논문과 관련해서 궁금한 내용이 있다면 원라인에이아이 AI팀에게 문의주시기 바랍니다.
Test-Time Scaling, multilingual 환경에서도 효과적일까?
기존 LLM에서는 성능 향상을 위해 학습 단계에서의 compute scaling 방법이 많이 사용되었지만, 시간이 지남에 따라 양질의 데이터의 부족으로 인해 학습에서의 compute scaling이 한계에 다다르고 있습니다. 이러한 상황에서 OpenAI의 O-series와 DeepSeek의 R1 모델들은 새로운 접근법으로 추론 단계(test-time)의 compute scaling에 주목하고 있습니다. 최근 각광받고 있는 test-time scaling 관련 연구들은 Chain-of-Thought (CoT) 프롬프팅과 같은 추론 강화 기법들이 특히 수학 및 코드 작성과 같은 태스크에서 효과적인 성능을 보여주고 있지만, 이러한 방법론들이 언어적 다양성이나 도메인 확장성에서도 안정적으로 작동할지는 여전히 불명확한 상태입니다.
"Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning" 논문에서는 이러한 의문점을 기반으로 "기존 train-time scaling에서 입증된 cross-lingual training의 효과가 test-time scaling에서도 동일한 효과를 보여줄까?" 라는 질문을 던집니다. 이를 탐구하기 위해 다국어 수학 추론 능력을 세밀하게 평가할 수 있는 벤치마크(MCLM)를 제안하고, Outcome Reward Modeling(ORM), Process Reward Modeling(PRM), Budget Forcing(BF)와 같은 대표적인 test-time scaling 기법의 성능을 다국어 환경에서 평가하며 각각의 test-time scaling 방법론이 다국어 환경에서 어떤 모습을 보여주는지 파헤칩니다.
Test-Time Scaling이 무엇일까?
Test-time scaling은 학습 과정에서뿐만 아니라, 추론 시점에서도 모델의 성능을 확장하기 위한 기법으로, 특히 복잡한 수학적 추론과 같은 난제에 적용되고 있습니다. 논문에서는 Test-Time Scaling 방법 중 많이 사용되는 Budget Forcing(BF), Outcome Reward Model(ORM), Process Reward Model(PRM)에 대해 중점적으로 살펴보았습니다.

Budget Forcing (BF): 이 방법은 s1에서 처음 제안되 방법론으로 추론 단계에서 주어진 계산량을 엄격히 제한하거나 확장하며 모델이 더욱 심도 깊은 사고를 하도록 유도합니다. 예를 들어서, 모델이 지정된 예산(budget)을 초과하거나 미달하는 경우, 추가적인 추론을 유도하거나 빠르게 결론짓도록 요구함으로써 성능 향상을 꾀하는 방식입니다.
Outcome Reward Model (ORM): ORM은 모델이 생성한 최종 응답을 기반으로 점수를 매기는 reward model의 한 종류로, 추론 과정에서 여러 개의 후보 답안을 생성한 후, 이 중 가장 높은 점수를 받은 답안을 최종적으로 선택하는 방식입니다.
Process Reward Model (PRM): PRM은 ORM과 달리 모델이 생성하는 응답을 단계별로 평가하면서 추론 과정 자체를 점진적으로 보상 모델을 통해 지도하며 답안을 생성하는 방법입니다. 각 추론 단계에서 여러 후보를 탐색하고, 이 중 최적의 방향으로 모델이 진전하도록 유도합니다.
Multilingual Competition Level Math (MCLM)
기존의 대표적인 다국어 수학 벤치마크로는 GSM8K를 번역한 MGSM이 널리 사용되어 왔습니다. 그러나 MGSM은 원본 벤치마크인 GSM8K가 초등학교 사칙연산 수준의 쉬운 문제로 구성되어 있어서, 최신 모델들이 이미 매우 높은 성능을 기록하며 벤치마크로서의 변별력이 현저히 떨어진 상황입니다. 따라서 이러한 다국어 수학 벤치마크의 부재는 일반적인 math word problem을 넘어 경시대회 수준의 난이도를 갖춘 새로운 다국어 수학 벤치마크가 필요하다는 점을 시사합니다.
MCLM은 이러한 다국어 수학 벤치마크의 부재 문제를 해결하기 위해 제안된 다국어 수학 추론 벤치마크로 55개의 언어로 이루어진 경진대회 수준 문제들로 구성되었습니다. 다음의 표는 해당 벤치마크의 각 서브셋에 대한 전반적인 통계치를 보여줍니다:

MT-MATH100: MATH-500 벤치마크에서 100개의 문제를 랜덤하게 샘플링하고,
gpt-4o를 활용하여 55개의 언어로 번역 진행MT-AIME2024: AIME2024 벤치마크의 전체 문제에 대해
gpt-4o를 활용하여 55개의 언어로 번역 진행MT-IMO: 2006년부터 2024년 까지의 IMO 문제 114개 중 증명 또는 이미지 기반 문제를 제외한 27개의 문제에 대해 38개 언어의 공식 번역 문제들을 수집
MT-MO: 각국에서 진행되는 수학 올림피아드 문제들을 모두 수집하여 총 11개의 언어에 대한 수학 올림피아드 문제 수집
다국어 환경에서의 Test-Time Scaling 파헤치기!
MCLM 벤치마크에서 3가지 test-time scaling 방법론 Budget Forcing (BF), Outcome Reward Model (ORM), Process Reward Model (PRM)을 적용하여 언어 간의 성능이 일관되게 유지되는지 실험하였습니다. 이때 다국어 환경에서 모델의 정확도를 확인하기 위해 다음의 두 가지 지표에서 평가를 진행했습니다.
Accuracy: 서로 다른 언어 모델 간의 문제 풀이 정확도를 평가
Cross-Lingual Consistency: 모델이 똑같은 문제에 대해서 서로 다른 언어로 풀이할 수 있는지 확인하기 위해 Fleiss' kappa를 측정하였습니다. Fleiss kappa는 다수의 annotator 간에 얼마나 일치하는 annotation을 하는지 평가하기 위한 지표인데, 이를 다국어 환경에서 언어 모델이 각 언어들에 대해 동일한 출력을 뽑아내는가를 평가하기 위해 사용했습니다.
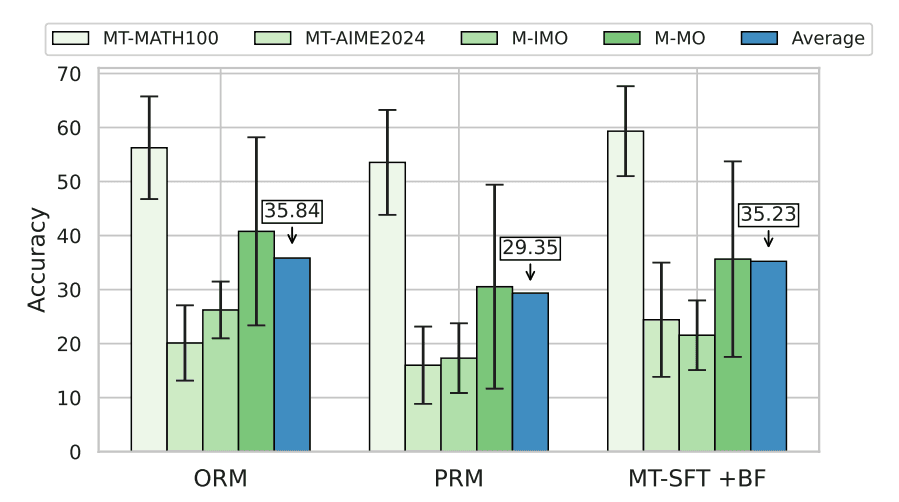
Outcome Reward Modeling (ORM)
Qwen2.5-Math-1.5B와 7B 모델을 사용해 문제당 K (with {2, 4, 8})개의 응답 생성 후, ORM을 통해 가장 높은 점수를 얻은 응답을 선택하는 방식으로 평가하였습니다. 그 결과, MT-MATH100 서브셋에서는 K의 값이 오름에 따라 성능이 꾸준히 향상되었으나, 더 어려운 서브셋인 MT-AIME2024의 경우 영어를 제외한 다른 언어에서는 유의미한 성능 향상을 보이지 않았습니다. 이러한 결과는 ORM이 영어 환경에서는 유의미한 scaling 전략이지만, 다른 언어에서는 고품질 candidate를 생성하는데 어려움을 겪으며 제한된 성능 향상을 보여준다고 유추할 수 있습니다.
Process Reward Modeling (PRM)
Qwen2.5-Math-1.5B 모델을 사용해 응답 생성 과정에서 매 단계마다 후보 응답을 생성하고 Qwen2.5-Math-PRM 7B & 72B reward model을 활용하여 가장 높은 점수를 얻는 후보 응답을 선택하는 방식으로 평가하였습니다. PRM 방법 역시 step의 수와 candidate의 수를 늘림에 따라 평균 성능이 약간 증가하였으나, 성능 편차나 언어 간의 일관성에서는 뚜렷한 개선점이 없었습니다.

ORM vs. PRM
ORM과 PRM 모두 다국어 환경에서 불안정한 성능 향상과 낮은 Fleiss' kappa 값을 보여줬음에도 불구하고, 다음의 이미지에서 확인할 수 있듯이 ORM은 평균 성능 측면에서 PRM을 능가하는 성능을 보여줍니다. 이는 똑같은 inference FLOPs가 주어졌을 때, PRM은 매 스텝마다 reward model을 불러오며 더 높은 latency를 만들어내기 때문이라고 볼 수 있습니다. 하단 이미지에서 파란선은 PRM, 초록선은 ORM을 의미합니다.

Budget Forcing (BF)
BF를 통한 모델의 다국어 수학 추론 능력 변화를 확인하기 위해 다음과 같은 세팅으로 학습시킨 모델을 대상으로 평가를 진행하였습니다:
Qwen2.5-Math-1.5B + SFT: OpenR1-220K 데이터셋에서 50K 샘플을 랜덤하게 뽑아서 3 epoch 학습
Qwen2.5-Math-1.5B + SFT w/ Translated Data: Qwen2.5-Math-1.5B + SFT 모델 학습에 사용한 데이터셋에서 영어 샘플을 14개의 언어로 번역하여 학습 데이터셋으로 사용. 이때 reasoning trace 자체는 영어로 남기고 question과 answer만 target language로 번역 진행.
DeepSeek-R1-1.5B + SFT w/ Translated Data (MR-1): Qwen2.5-Math-1.5B + SFT w/ Translated Data에서 사용한 학습 데이터셋으로DeepSeek-R1-1.5B 모델에서 학습. 학습을 길게 진행할 경우 성능 저하가 발생하는 것을 관찰하여, 이를 완화하기 위해 0.5 epoch 학습만 진행.
해당 모델들에 대한 평가 결과로 다음과 같은 분석 결과를 도출하였습니다:
번역 데이터를 사용한 학습은 English-only 데이터를 사용하는 것에 비해 그리 큰 성능 향상을 보이지는 않음.
multilingual 데이터로 학습 시 초반에는 조금 낮은 정확도를 보여주지만, 학습이 진행됨에 따라 오르는 것을 확인.
DeepSeek-R1은 매우 소수의 데이터로 학습했음에도 불구하고 빠른 성능 향상을 보여주는데, 이는 reasoning model이 더 빠르게 multilingual data에서 베네핏을 가진다는 것을 보여줌. 이는 모델이 이미 가지고 있는 self-correction 능력이 multilingual setting으로 증대되는 것으로 볼 수 있음.

해당 모델들을 활용하여 {2048, 4096, 8192}의 다양한 BF 세팅에서 실험을 한 결과, 영어에서는 꾸준하게 성능 향상을 보여줬지만, 대부분의 다른 언어에 대해서는 제한된 성능 향상이 일어났습니다. 실제로도 BF가 2048에서 8192로 늘어남에 따라 평균 성능은 고작 1.9% 정도밖에 증가하지 않았습니다.

마치며..
MCLM에서의 Outcome Reward Modeling(ORM), Process Reward Modeling(PRM), Budget Forcing(BF), 이 세 가지 test-time scaling 방법론의 평가 결과는 test-time scaling 방법들이 영어 환경에서는 뚜렷한 성능 향상을 가져오지만, 그 성과가 다른 언어로 일반화되는 데 한계가 있음을 분명히 보여주었습니다. 이러한 결과는 다국어 환경에서 LLM의 test-time scaling 방법의 한계를 명확히 드러내고, 향후 연구가 다국어 일반화 능력 향상에 집중해야 할 필요성을 강조하였습니다.
References
📝 Paper: https://arxiv.org/abs/2502.17407
🤗 Dataset: https://huggingface.co/datasets/amphora/MCLM
🖥️ GitHub: https://github.com/gauss5930/MCLM
