Test-Time Scaling in Multilingual Environments: Does it Really Work?
날짜
2025. 5. 30.
카테고리
Research
This post covers an analysis of the effectiveness of Test-Time Scaling for LLMs in multilingual settings, based on the paper "Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning". This paper was accepted in the ACL 2025 Main Track.
This series reviews papers published by OnelineAI. If you have any questions about paper, please contact the AI team on OnelineAI.
Is Test-Time Scaling effective even in multilingual settings?
In conventional large language models (LLMs), compute scaling during the training phase has often been used to improve performance. However, over time, this approach has reached its limits due to a shortage of high-quality data. In response to this, OpenAI's O-series and DeepSeek's R1 models are turning their attention to compute scaling during the inference phase, or test-time. Recent studies on test-time scaling, which have been gaining traction, highlight that inference-enhancing techniques like Chain-of-Thought (CoT) prompting deliver strong performance, especially in tasks involving mathematics and code generation. Still, it remains unclear whether these methods operate reliably across different languages or in broader domains.
The paper "Linguistic Generalizability of Test-Time Scaling in Mathematical Reasoning" raises the question, "Can the cross-lingual training effectiveness demonstrated in traditional train-time scaling also apply to test-time scaling?" To explore this, the authors propose a benchmark (MCLM) capable of finely evaluating multilingual mathematical reasoning abilities. They assess the performance of representative test-time scaling techniques such as Outcome Reward Modeling (ORM), Process Reward Modeling (PRM), and Budget Forcing (BF) in multilingual settings, investigating how each of these methods performs in diverse linguistic environments.
What is Test-Time Scaling?
Test-time scaling is a technique used not only during the training phase but also at inference time to enhance a model's performance. It is particularly applied to challenging tasks such as complex mathematical reasoning. The paper focuses on commonly used Test-Time Scaling methods: Budget Forcing (BF), Outcome Reward Model (ORM), and Process Reward Model (PRM).

Budget Forcing (BF): This method was first proposed in s1. It strictly constrains or extends the computational budget during the inference phase, encouraging the model to engage in deeper reasoning. For example, if the model exceeds or falls short of the designated budget, it is prompted to either conduct additional inference or conclude more quickly, aiming to improve overall performance.
Outcome Reward Modeling (ORM): ORM is a type of reward model that assigns scores based on the model's final responses. During inference, the model generates multiple candidate answers and selects the one with the highest score as the final answer.
Process Reward Modeling (PRM): Unlike ORM, PRM evaluates the response generation process step-by-step. It guides the inference process progressively through a reward model while the answer is being generated. At each inference step, multiple candidates are explored and the model is steered toward the most optimal path.
Multilingual Competition Level Math (MCLM)
A widely used multilingual math benchmark has been MGSM, a translated version of the original GSM8K. However, MGSM lacks strong discriminatory power as a benchmark because the original GSM8K mainly consists of elementary-level arithmetic problems, and modern models have already achieved very high performance on it. This indicates a need for a new multilingual math benchmark that goes beyond general math word problems and reaches the level of difficulty found in math competitions.
MCLM is a multilingual mathematical reasoning benchmark proposed to address this gap. It consists of competition-level problems translated into 55 languages. The following table presents general statistics for each subset of this benchmark:

MT-MATH100: 100 problems randomly sampled from the MATH-500 benchmark and translated into 55 languages using GPT-4o
MT-AIME2024: All problems from the AIME2024 benchmark translated into 55 languages using GPT-4o
MT-IMO: Out of 114 IMO problems from 2006 to 2024, 27 problems (excluding proof or image-based ones) were collected along with their official translations in 38 languages
MT-MO: Math Olympiad problems from various countries were collected, covering problems in 11 different languages
다국어 환경에서의 Test-Time Scaling 파헤치기!
In the MCLM benchmark, we applied three test-time scaling methods—Budget Forcing (BF), Outcome Reward Model (ORM), and Process Reward Model (PRM)—to examine whether performance remains consistent across languages. To evaluate the model's accuracy in a multilingual setting, we used the following two metrics:
Accuracy: Measures the problem-solving accuracy across different language models.
Cross-Lingual Consistency: Assessed by calculating Fleiss' kappa to determine whether the model can solve the same problem in different languages. Fleiss' kappa is a metric used to evaluate the agreement among multiple annotators, and in this context, it is used to measure whether the language model produces consistent outputs across different languages.
Outcome Reward Modeling (ORM)
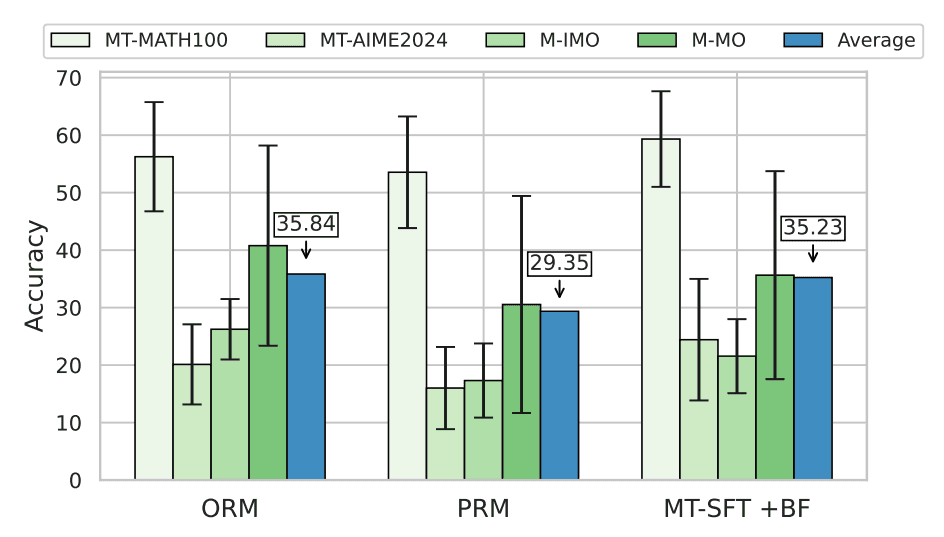
We evaluated performance by generating K responses per question (with K ∈ {2, 4, 8}) using the Qwen2.5-Math-1.5B and 7B models, then selecting the highest-scoring response through ORM. As a result, in the MT-MATH100 subset, performance consistently improved as K increased. However, in the more challenging MT-AIME2024 subset, there was no significant performance improvement in languages other than English. These findings suggest that while ORM serves as an effective scaling strategy in English settings, it struggles to produce high-quality candidates in other languages, leading to limited performance gains.
Process Reward Modeling (PRM)
We evaluated the model by generating candidate responses at each step using the Qwen2.5-Math-1.5B model and selecting the candidate with the highest score using the Qwen2.5-Math-PRM 7B and 72B reward models. While the PRM method showed a slight improvement in average performance as the number of steps and candidates increased, there were no clear improvements in performance variance or consistency across languages.

ORM vs. PRM
Despite both ORM and PRM showing unstable performance improvements and low Fleiss' kappa values in a multilingual environment, ORM demonstrates superior average performance compared to PRM, as seen in the image below. This can be attributed to PRM loading the reward model at every step, resulting in higher latency when given the same inference FLOPs. In the image below, the blue line represents PRM, and the green line represents ORM.

Budget Forcing (BF)
To examine how the model's multilingual mathematical reasoning capabilities change through BF (presumably "Backbone Fine-tuning"), we evaluated models trained under the following settings:
Qwen2.5-Math-1.5B + SFT: Trained for 3 epochs using 50K randomly selected samples from the OpenR1-220K dataset.
Qwen2.5-Math-1.5B + SFT w/ Translated Data: Trained on a dataset where the English samples used in the Qwen2.5-Math-1.5B + SFT training were translated into 14 target languages. Only the question and answer were translated into the target language, while the reasoning trace remained in English.
DeepSeek-R1-1.5B + SFT w/ Translated Data (MR-1): The DeepSeek-R1-1.5B model was trained using the same translated dataset used for the previous setting. Observing a performance drop with longer training, only 0.5 epochs were used to mitigate this issue.
Based on the evaluation of these models, we derived the following insights:
Training with translated data does not yield significant performance improvements compared to using English-only data.
When training with multilingual data, the model shows slightly lower initial accuracy but improves as training progresses.
Despite being trained on a small amount of data, DeepSeek-R1 shows rapid performance improvement, suggesting that reasoning models benefit more quickly from multilingual data. This indicates that the model’s inherent self-correction ability becomes enhanced in a multilingual setting.

Using the models in question, experiments were conducted with various BF settings of {2048, 4096, 8192}. In English, there was a consistent improvement in performance, but for most other languages, the performance gains were limited. In fact, as the BF increased from 2048 to 8192, the average performance only improved by about 1.9%.

Conclusion
The evaluation results of the three test-time scaling methods used in MCLM — Outcome Reward Modeling (ORM), Process Reward Modeling (PRM), and Budget Forcing (BF) — clearly demonstrated that while these methods lead to significant performance improvements in English environments, their effectiveness does not generalize well to other languages. These findings highlight the limitations of test-time scaling approaches for LLMs in multilingual settings and underscore the need for future research to focus on enhancing multilingual generalization capabilities.
References
📝 Paper: https://arxiv.org/abs/2502.17407
🤗 Dataset: https://huggingface.co/datasets/amphora/MCLM
🖥️ GitHub: https://github.com/gauss5930/MCLM
