차세대 한국어 추론 모델, Ko-R1-3 개발기 (2025.07.11)
날짜
2025. 7. 14.
카테고리
Research

Ko-R1-3 개발의 시작
2년 전, Stanford의 Alpaca가 오픈소스 LLM 개발 연구의 새로운 패러다임을 제시했을 때, HAE-RAE는 한국어 언어 모델의 기준을 세우고자 하는 목적으로 결성했습니다. 한국어 모델 평가의 표준을 정립하겠다는 목표 아래, 지난 2년간 KMMLU, HAE-RAE Bench, HRM8K 등 다양한 벤치마크를 공개하며 국내 NLP 연구 생태계에 기여해왔습니다.
올해 초, 강력한 추론 성능을 보여준 DeepSeek-R1의 등장은 벤치마크 구축을 넘어, 직접 모델 개발에 뛰어들게 만들었습니다. 그 첫 결과물인 Ko-R1은 수학 추론 문제에서 인상적인 성능을 보였지만, 간단한 일상 질문에는 제대로 답하지 못하는 등 특정 영역에서의 명확한 한계를 드러냈습니다.
이러한 경험을 바탕으로 OnelineAI, HAE-RAE, KISTI는 함께 협력하여 Ko-R1의 한계를 극복하고 다음과 같은 강점을 갖춘 차세대 한국어 추론 모델, Ko-R1-3 개발에 착수했습니다.
강력한 성능: 추론 능력은 물론, 다방면의 벤치마크에서 강력한 성능을 입증하는 모델
일상 질문에 대한 강건성: 지식/추론 질문을 넘어, 일상적인 대화에서도 뛰어난 강건성(Robustness)을 갖춘 모델
유연한 추론 제어: 사용자의 기호에 따라
think/not_think모드를 유연하게 제어할 수 있는 모델높은 신뢰도: 안전성(Safety)을 확보하여 누구나 믿고 사용할 수 있는 모델
이번 포스팅에서는 Ko-R1-3 개발 초기에 마주했던 문제들과 문제 해결을 위해 찾아낸 솔루션을 공유하고자 합니다.
데이터셋 수집
모델 학습에 앞서, 모델이 추론 문제뿐만 아니라 일상적인 질문에도 강건하게(robust) 대답할 수 있도록 기반을 다지는 데 주력했습니다. 이를 위해 지난 2개월간 다양한 온라인 커뮤니티와 웹페이지에서 약 700만 건의 데이터를 수집했습니다. 수집한 데이터는 중복 제거(deduplication)와 이미지 제거 등의 후처리 과정을 거쳤습니다. 이후 Qwen3-32B 모델을 활용해 약 200만 건의 추론 데이터를 생성(증강)하여 최종 학습 데이터셋을 준비했습니다. (※ 제거된 이미지 데이터는 추후 공개할 VLM 벤치마크 제작에 활용될 예정입니다.)
모델 학습과 시행착오
Loss Spikes
전체 데이터셋에서 샘플링한 13만 건(130K)의 데이터로 Magistral-24B 모델 학습을 시작하자마자 이상 징후를 발견했습니다. 아래 그래프에서 볼 수 있듯, Loss가 비정상적으로 급등하는 스파이크(spike) 현상이 나타났고, 이는 학습 데이터에 문제가 있음을 시사했습니다. 원인 파악을 위해 해당 구간(89~91번 배치)의 데이터를 분석한 결과, 의도했던 '영어 추론 & 한국어 응답' 데이터가 아닌 영어로만 구성된 데이터가 포함된 것이 원인이었습니다.
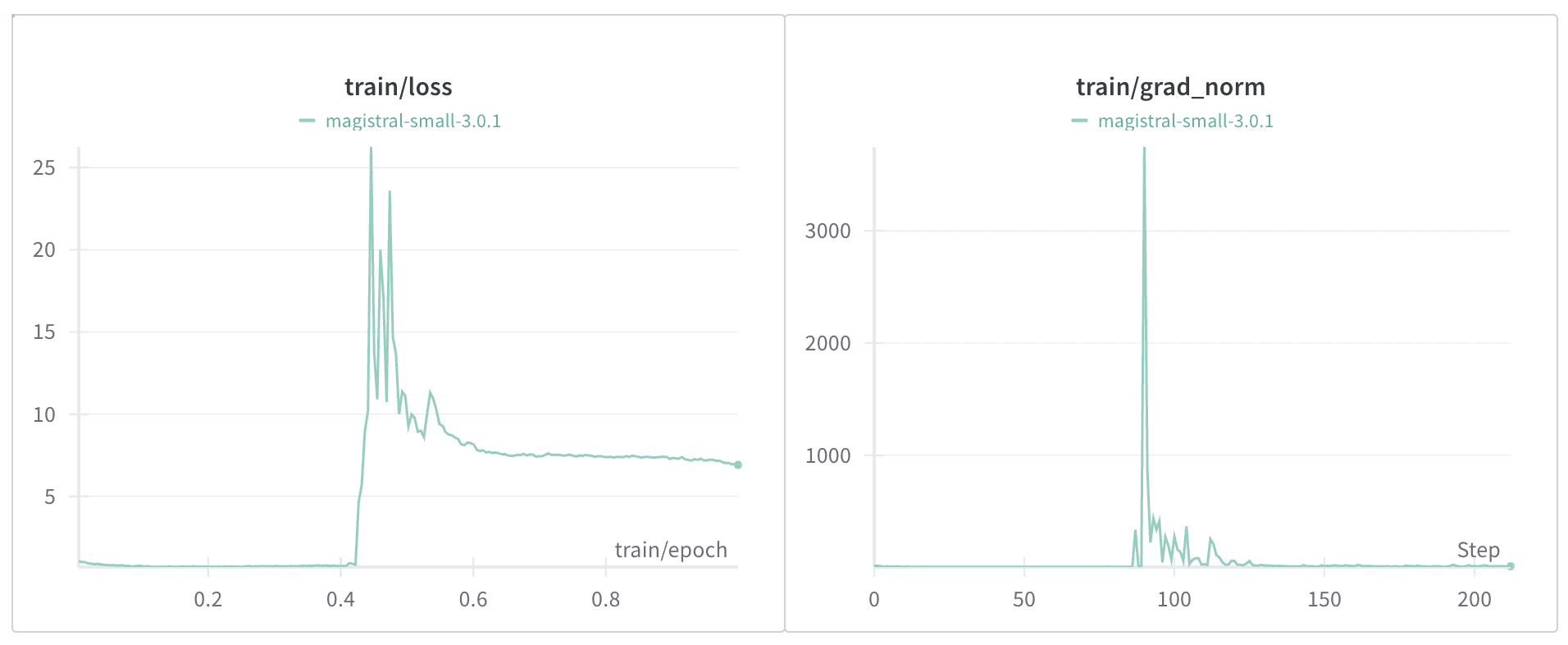
학습의 안정성을 위해, 다음 기준을 만족하는 샘플만 필터링하는 코드를 적용했습니다.
각 샘플에
<think> … </think>태그가 하나만 존재할 것</think>태그 이후에 생성된 응답 중 한국어 토큰의 수
Loss Drifts
Loss Spike 문제를 해결한 직후, 오히려 loss가 급격히 증가하는 현상이 발생했습니다. 해당 현상의 원인을 모델이 local minimum에 빠진 것으로 판단하고, 다음과 같이 하이퍼파라미터를 조정하여 loss curve를 안정시켰습니다.
Learning Rate 감축
Weight Decay 증가
Warm-up 스텝 감축
Optimizer 변경 (8-bit → AdamW)
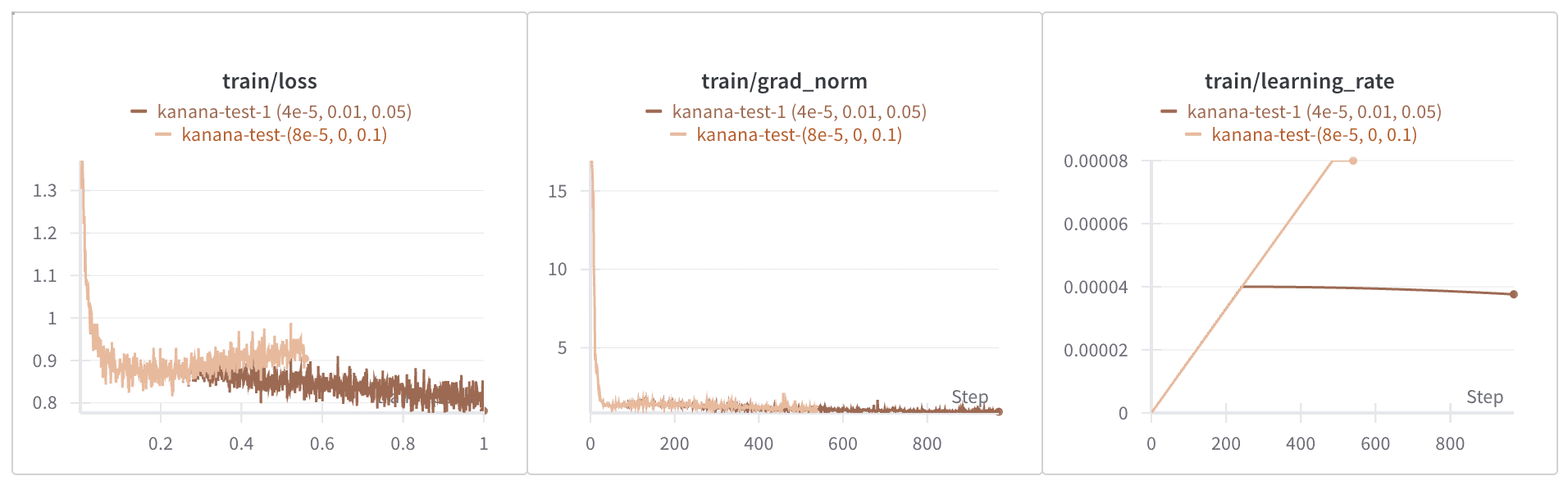
데이터셋과 하이퍼파라미터 설정이 안정화된 후, 학습 모델을 Kanana-8B-Instruct로 교체했습니다. Kanana 모델에 learning rate를 높게 설정하자 loss curve가 다시 우상향하는 현상을 확인하고, learning rate를 다시 한번 낮추는 작업을 진행했습니다.

최적의 데이터셋 구성
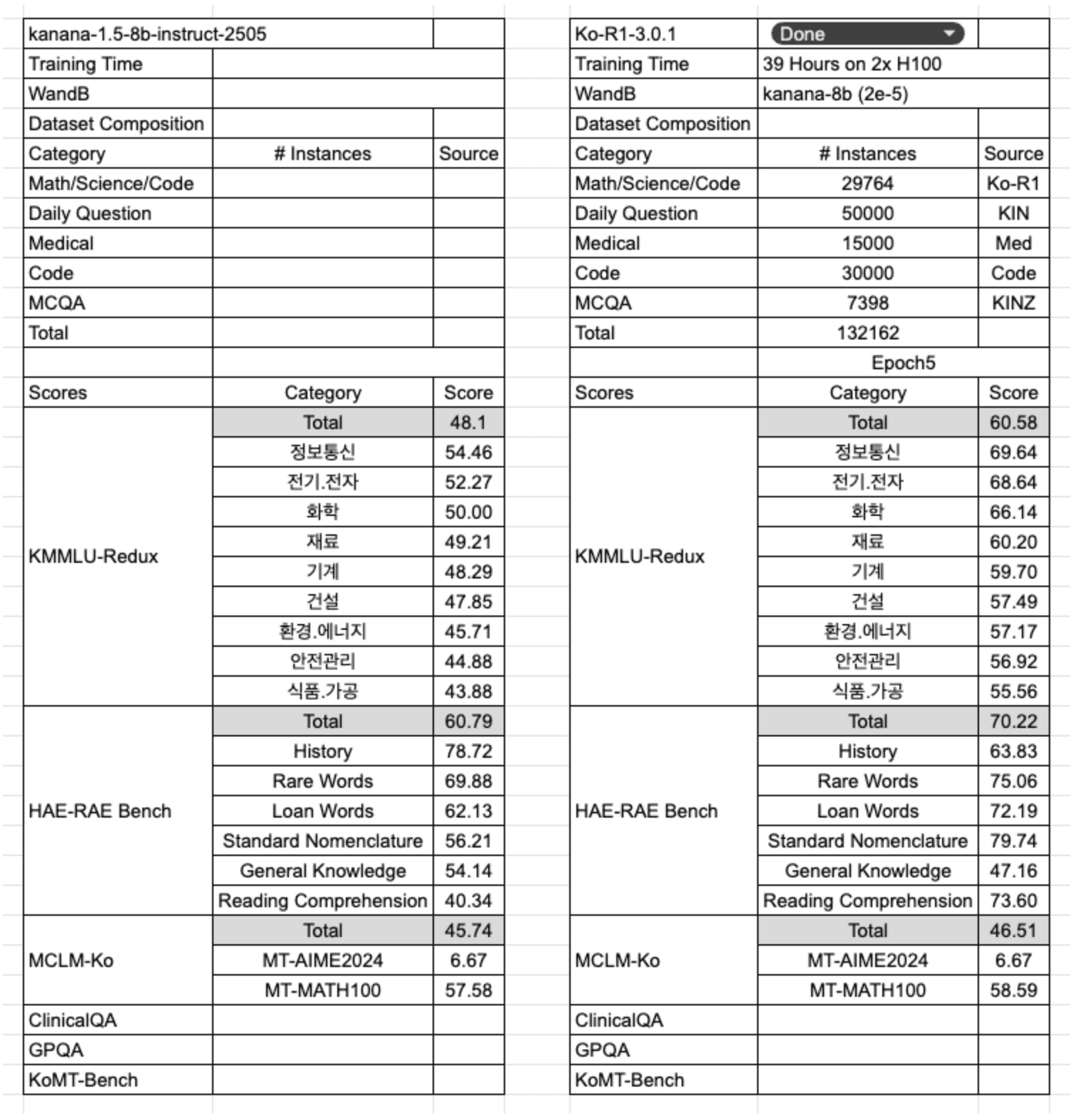
1st run - Ko-R1-3.0.1
샘플 데이터셋으로 5 epoch의 초기 학습을 진행한 결과(그래프의 보라색 커브), MCQA 벤치마크(KMMLU-Redux, HAE-RAE Bench)에서는 성능이 향상되었지만, MCLM-ko(AIME2024, MATH)에서는 유의미한 개선이 없었습니다. 이는 모델이 추론 모델의 핵심 역량을 보여주어야 할 수학, 과학, 코딩과 같은 고난도 태스크에서 성능이 정체되었다는 의미였기에, 좋지 않은 신호였습니다.
2nd run - Ko-R1-3.0.2
첫 번째 학습 이후, 데이터셋 구성을 다음과 같이 변경하여 모델 학습을 진행했습니다. 먼저, 기존 Ko-R1 데이터셋에 포함된 수학 및 과학 데이터를 더 높은 품질의 OpenThought3 데이터셋으로 교체했습니다. 이 과정에서 OpenThought3 샘플은 Gemini-2.0-Flash 모델을 이용해 한국어로 번역하고, Qwen3-32B 모델로 한국어 응답을 생성했습니다. 또한, 데이터 포맷팅이 모델 성능에 미치는 영향을 확인하고자 MCQA 유형의 KINZ 데이터셋을 학습에서 제외했습니다.
학습 모델 평가 결과는 예상과 정확히 일치했습니다. MCLM-Ko에서는 성능이 상승했지만, KMMLU-Redux와 HAE-RAE Bench에서는 성능이 하락하는 경향을 보였습니다. 이 실험을 통해 두 가지 중요한 사실을 명확히 확인할 수 있었습니다: 첫째, OpenThought 데이터셋이 모델의 수학적 추론 능력 향상에 핵심적인 역할을 한다는 것. 둘째, MCQA 형식의 학습 데이터가 동일한 형식의 벤치마크 성능에 결정적인 영향을 미친다는 것입니다.
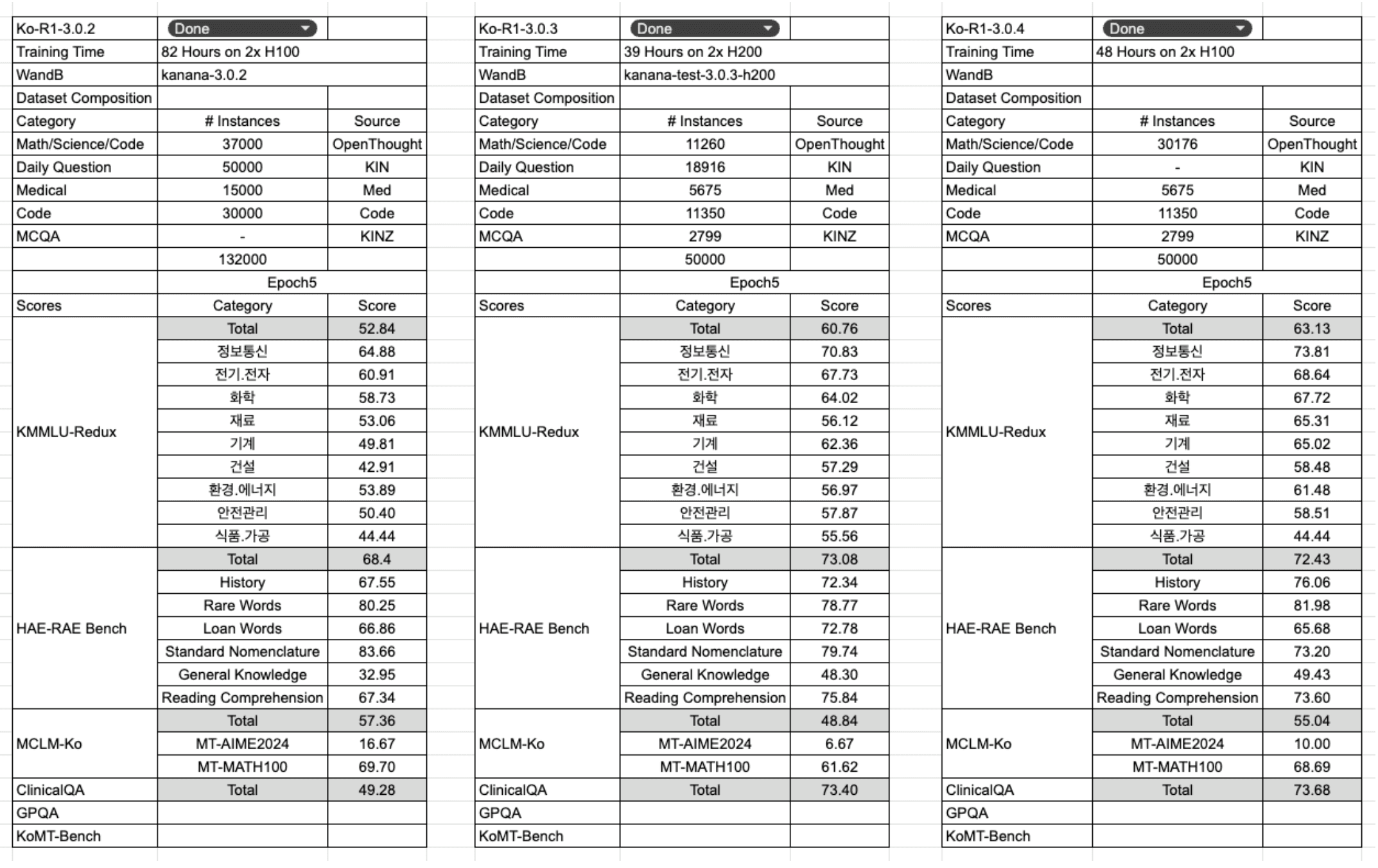
3rd run - Ko-R1-3.0.3
두 번째 학습 이후, 기존 데이터셋의 카테고리 분포는 그대로 유지하면서 전체 크기만 약 30%인 50k로 샘플링하여 학습 효율을 점검했습니다. 흥미롭게도 단 2.7k의 MCQA 샘플만으로 KMMLU-Redux와 HAE-RAE Bench 벤치마크에서 기존 모델과 대등한 수준의 성능을 복원할 수 있었습니다. 하지만 MCLM-ko 벤치마크에서는 상대적으로 성능 개선이 더딘 모습을 보여, 추가적인 보완이 필요함을 시사했습니다.
4th run - Ko-R1-3.0.4
데이터 샘플 수는 50k로 유지하면서, 'daily question'을 'OpenThought' 데이터로 교체했습니다. 그 결과, 절반의 학습 비용만으로도 대부분의 벤치마크에서 두 번째 학습과 거의 비슷한 수준의 성능을 달성할 수 있었습니다.
Takeaways & Future Plans
Ko-R1-3 개발을 진행하며 다음과 같은 세 가지 중요한 사실을 확인할 수 있었습니다.
OpenThought 데이터의 확장성: OpenThought 데이터셋은 그 규모가 커질수록 모델의 성능 향상에 비례하여 기여하는, 뚜렷한 scaling의 효고라르 보여주었습니다.
MCQA 데이터의 중요성: 추론 벤치마크 뿐만 아니라 MCQA 벤치마크에서도 높은 점수를 달성하기 위해서는 MCQA 형식의 데이터가 필수적이라는 점을 다시 한번 확인했습니다.
'일상 질문' 데이터의 미미한 영향: 반면, 'daily-question' 데이터는 현재 사용 중인 벤치마크 점수에는 눈에 띄는 영향을 주지 않는 것으로 나타났습니다.
물론 'daily-question' 데이터의 효과가 없다고 단정하기는 이릅니다. 이는 현재의 벤치마크가 해당 데이터가 주는 이점을 측정하는데 초점을 두고 만들어지지 않았기 때문입니다. 따라서 이 능력을 정밀하게 평가하기 위한 새로운 테스트를 진행하며, OpenThought 외 다른 데이터셋에서도 유의미한 확장성을 보이는 조합이 있는지 탐색할 계획입니다.
References
📝 Original Post - Link
