I SPOT the errors!
Date
May 30, 2025
Category
Research

"When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research" 논문을 기반으로 다국어 환경에서 LLM의 Test-Time Scaling의 효과에 대해 분석하는 내용을 다루고 있습니다.
이 시리즈는 원라인에이아이에서 발표한 논문을 리뷰합니다. 논문과 관련해서 궁금한 내용이 있다면 원라인에이아이 AI팀에게 문의주시기 바랍니다.
AI Co-Scientist의 가능성, 검증에서는 어떨까?
최근 LLM의 발전으로 인해 다양한 분야에서 자동화된 연구가 주목받고 있습니다. 이러한 흐름 속에서 이른바 'AI 연구자(AI Co-Scientists)'라는 개념이 등장하여 과학적 발견 과정에서 가설 생성부터 논문 작성까지 인간 연구자의 역할을 부분적으로 대체하거나 보완하고 있습니다. 그러나 연구의 결과물을 생성하는 역할에서의 성공에도 불구하고, 학술 논문의 내용을 검증하거나 오류를 찾아내는 '검증자'로서의 능력은 아직까지 충분히 탐구되지 않았습니다.
원라인에이아이 연구팀은 바로 이 지점에 초점을 맞추면서 LLM의 학술 검증 능력을 평가하기 위한 벤치마크 데이터셋인 SPOT(Scientific Paper Error Detection)를 제안했습니다. SPOT은 실제로 출판된 논문 83편을 바탕으로 구성된 데이터셋으로, 이 논문들에서 저자가 인정한 오류 또는 논문이 철회된 사례와 같은 실질적인 오류를 추출하여 제작되었습니다.
연구팀은 해당 벤치마크 데이터셋을 활용하여 최신 Multi-modal LLM들이 과학적 오류를 얼마나 잘 식별할 수 있는지 실험하고 평가하며, 현재 모델들의 verifier로써의 부족함을 분석하였습니다. 본 포스팅에서는 "When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research" 논문을 토대로 SPOT 벤치마크가 무엇인지 살펴보고 최신 모델들이 과학적 검증자로써 어느 정도의 역량을 보여주는지 심층적으로 분석해보겠습니다.
Watch out! I SPOT the errors!
SPOT은 2024년 이후 발표된 최신 과학 논문 83편을 기반으로 구축된 multi-modal error detection 벤치마크로, 실제 논문에서 저자들이 인정하고 정정이나 철회를 해야 했던 중대한 오류 91개를 포함하고 있습니다. 또한 논문 한 편 당 약 12,887개의 토큰과 약 18개의 이미지를 포함하고 있어, 기존의 오류 타 오류 검증 데이터셋보다 훨씬 복잡하고 포괄적인 자료를 제공합니다. 이러한 SPOT 벤치마크는 다음의 5단계의 과정을 거쳐서 제작되었습니다:
초기 자료 수집: WithdrarXiv와 PubPeer에서 오류가 보고된 논문을 선별합니다.
자동 필터링: GPT-4o 모델을 이용하여 모호성이 없고 명확한 오류만을 필터링합니다.
저자의 오류 인정 확인: 논문의 저자가 직접 인정한 오류만을 데이터셋에 포함시킵니다.
휴먼 어노테이션: 휴먼 어노테이터가 명시성과 중대성을 확인하여 추가적으로 오류를 점검합니다.
데이터 정규화: 최종적으로 OCR 기술을 통해 PDF에서 텍스트와 이미지 데이터를 정규화하여 오류의 명확한 검증이 가능하도록 처리합니다.
위와 같은 과정을 거쳐서 만들어진 SPOT은 다음의 10개의 리서치 도메인의 논문을 커버하면서 6가지 유형의 오류를 다루고 있습니다:
Research Domains: Mathematics, Physics, Biology, Chemistry, Materials Science, Medicine, Environmental Science, Engineering, Computer Science, Multidisciplinary
Error Types: Equation / proof, Figure duplication, Data inconsistency, Statistical Reporting, Reagent Identity, Experiment Setup

SPOT은 모델의 과학 논문 오류 탐지 및 검증 성능을 평가하기 위해 다음의 세 가지 주요 평가 메트릭을 활용합니다:
Precision: 모델이 지적한 오류 중 실제로 정답으로 확인된 오류의 비율.
Recall: SPOT 데이터셋에서 인간이 확인한 모든 실제 오류 중에서 모델이 얼마나 많은 오류를 정확히 발견했는가를 측정.
pass@K: 모델이 논문 한 편에 대해 K회 오류 탐지를 시도했을 때, 적어도 한 번이라도 실패 오류를 찾아내는가를 평가하는 지표.
현재 Multi-modal Model은 오류를 잘 SPOT할 수 있을까?
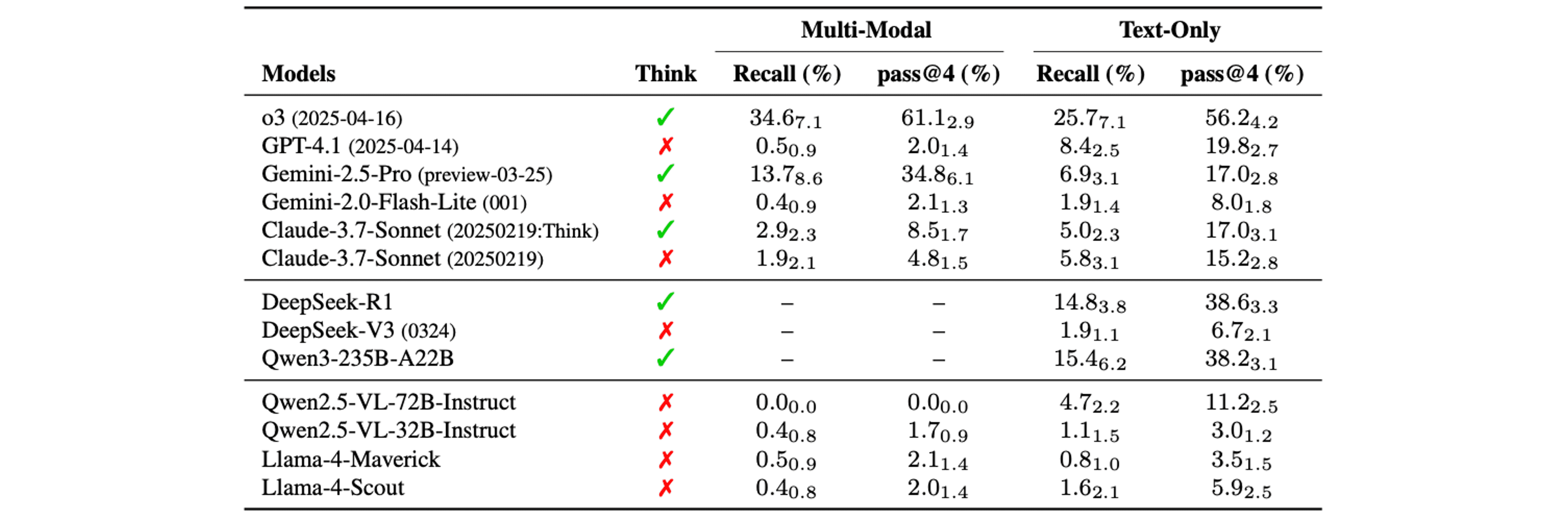
여러 proprietary 및 open-source multi-modal model들에 대한 SPOT 벤치마크 평가를 통해 다음과 같은 분석들을 확인하였습니다.
상당한 난이도: open-source model들은 multi-modal 환경에서 거의 0점에 가까운 성능을 보여주며 오류 탐지에 어려움을 겪었고, text-only 환경에서는 multi-modal 환경보다는 조금 더 높은 성능을 보여줬습니다. 또한 proprietary model들도 o3와 Gemini-2.5-Pro를 제외하고는 거의 0점에 가까운 성능을 보여주며 오류 탐지에 어려움이 있는 모습을 보여줍니다.
모델의 Multi-modal 환경 활용: 논문을 이해하는데에는 글 뿐만 아니라 이미지도 중요하게 작용합니다. 하지만 결과를 살펴보면 대부분의 모델들이 multi-modal 환경보다 text-only 환경에서 더 뛰어난 성능을 보여주는 것을 확인할 수 있습니다. 이는 대부분의 모델들이 오류 탐지를 진행하는데 이미지 정보를 제대로 활용하지 못하고 있다는 것을 암시하며, 오직 o3와 Gemini-2.5-Pro 만이 text-only 환경에서 multi-modal 환경보다 떨어지는 성능을 보여주며 이미지 정보를 제대로 참고하고 있다는 것을 확인할 수 있습니다.

추가적으로 각 모델의 confidence와 pass@4 성능을 확인해보면 신기한 결과를 확인할 수 있습니다. 위 그림의 우측 그래프를 보면 o3는 Statistical reporting 오류에서 모든 정답을 맞추고 그 외의 모델들도 상당히 높은 정확도를 보여주고 있지만, 모든 모델의 confidence가 0.5를 넘기지 못하는 것으로 보아 모델이 확신을 가지고 오류를 탐지해낸다기 보다는 찍어서 맞추는 경우에 더 가깝다는 것을 보여줍니다.
마치며..
LLM은 이제 단순히 컴퓨터 과학 분야뿐 아니라 다양한 과학 도메인에서도 강력한 성능을 보이고 있습니다. 이에 따라 가설을 세우고 실험을 진행하는 AI Co-Scientist 역할뿐 아니라 연구의 무결성을 검증하는 역할 또한 점점 더 중요해지고 있습니다. 원라인에이아이 연구팀에서 발표한 "When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research" 논문에서는 SPOT 벤치마크를 통해 다양한 언어 모델들이 검증자로서 가진 가능성을 분석하였습니다.
실험 결과는 o3나 Gemini-2.5-Pro와 같은 고성능 모델이 아니라면 multi-modal 데이터를 제대로 활용하기 어렵고, 심지어 이런 고성능 언어 모델들조차 매우 낮은 신뢰도(confidence)로 신뢰할 수 없는 검증 결과를 내놓는다는 것을 보여줍니다. 이와 같은 결과는 현재 언어 모델들이 AI Co-Scientist로서 여전히 부족한 점이 많음을 시사합니다. 앞으로 SPOT 벤치마크와 공개된 실험 결과를 바탕으로 AI Co-Scientist가 신뢰할 수 있는 검증자의 역할을 수행할 수 있도록 활발한 후속 연구가 이루어지길 바랍니다.
References
📝 Paper: https://arxiv.org/abs/2505.11855
🤗 Dataset: https://huggingface.co/datasets/amphora/SPOT-MetaData
🖥️ GitHub: https://github.com/guijinSON/SPOT
