I SPOT the errors!
Date
May 30, 2025
Category
Research
"When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research" 논문을 기반으로 다국어 환경에서 LLM의 Test-Time Scaling의 효과에 대해 분석하는 내용을 다루고 있습니다.
이 시리즈는 원라인에이아이에서 발표한 논문을 리뷰합니다. 논문과 관련해서 궁금한 내용이 있다면 원라인에이아이 AI팀에게 문의주시기 바랍니다.
The potential of AI Co-Scientists: What about verification?
With the recent advances in large language models (LLMs), automated research is gaining attention across various fields. Amid this trend, the concept of so-called "AI Co-Scientists" has emerged, where AI systems partially replace or complement human researchers in the scientific discovery process, from hypothesis generation to writing papers. However, despite their success in generating research outcomes, their capabilities as "verifiers" — identifying errors or validating the content of academic papers — have not been thoroughly explored.
Focusing precisely on this gap, the research team at OneLineAI proposed a benchmark dataset called SPOT (Scientific Paper Error Detection) to evaluate the academic verification abilities of LLMs. SPOT is a dataset based on 83 published papers, compiled by extracting actual errors acknowledged by the authors or found in retracted papers.
Using this benchmark dataset, the team conducted experiments to assess how well state-of-the-art multi-modal LLMs can detect scientific errors. They also analyzed the current limitations of these models as verifiers. In this post, we take a closer look at what the SPOT benchmark entails, based on the paper "When AI Co-Scientists Fail: SPOT — a Benchmark for Automated Verification of Scientific Research," and deeply examine how capable the latest models are in serving as scientific verifiers.
Watch out! I SPOT the errors!
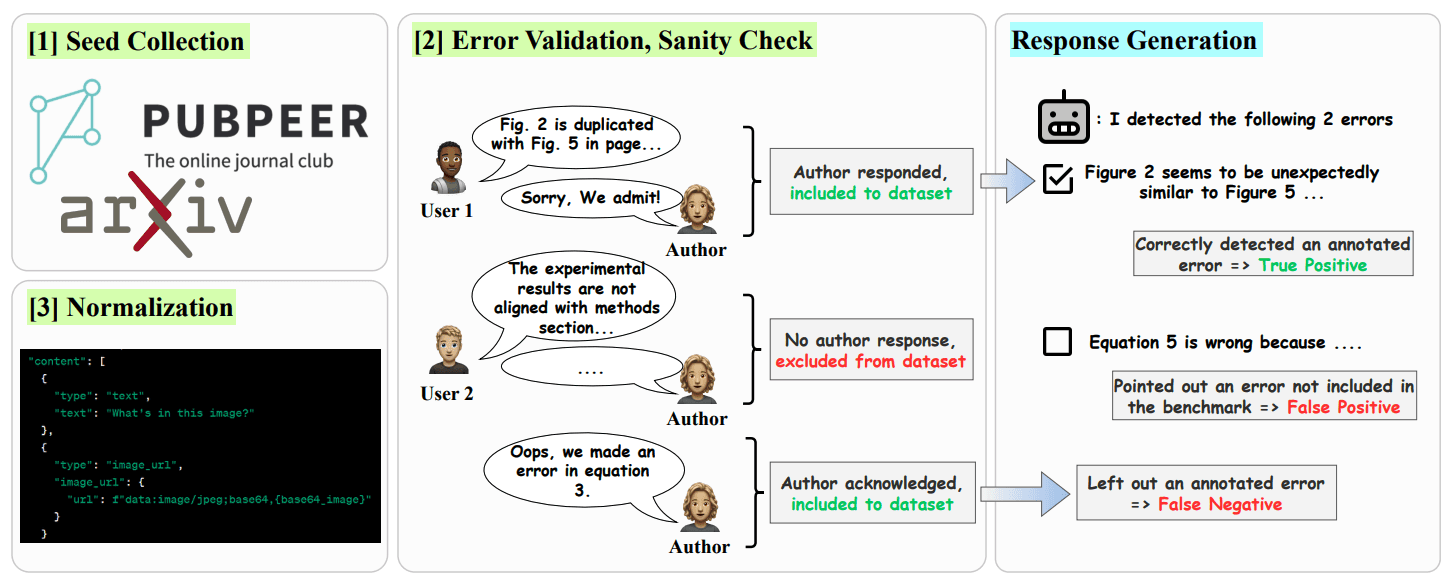
SPOT is a multi-modal error detection benchmark built upon 83 recent scientific papers published after 2024. It includes 91 significant errors that authors themselves acknowledged and either corrected or retracted in their actual papers. Each paper in the dataset contains approximately 12,887 tokens and around 18 images, making SPOT far more complex and comprehensive than existing datasets for error validation. The SPOT benchmark was created through the following five-step process:
Initial Data Collection: Papers with reported errors were selected from WithdrarXiv and PubPeer.
Automated Filtering: The GPT-4o model was used to filter for clear and unambiguous errors.
Author Confirmation: Only errors acknowledged by the original authors were included in the dataset.
Human Annotation: Human annotators reviewed and validated errors for clarity and severity.
Data Normalization: Finally, OCR technology was used to extract and standardize text and image data from PDFs, enabling precise verification of the errors.
Through this process, SPOT covers papers from the following ten research domains and addresses six types of errors:
Research Domains: Mathematics, Physics, Biology, Chemistry, Materials Science, Medicine, Environmental Science, Engineering, Computer Science, Multidisciplinary
Error Types: Equation or proof, Figure duplication, Data inconsistency, Statistical reporting, Reagent identity, Experiment setup

SPOT uses the following three key evaluation metrics to assess the model's performance in detecting and verifying errors in scientific papers:
Precision: The proportion of errors identified by the model that are actually confirmed as real errors.
Recall: Measures how many of the real errors identified by humans in the SPOT dataset are correctly detected by the model.
pass@K: An indicator that evaluates whether the model can identify at least one actual error when it attempts error detection K times on a single paper.
Can the current models effectively SPOT errors?
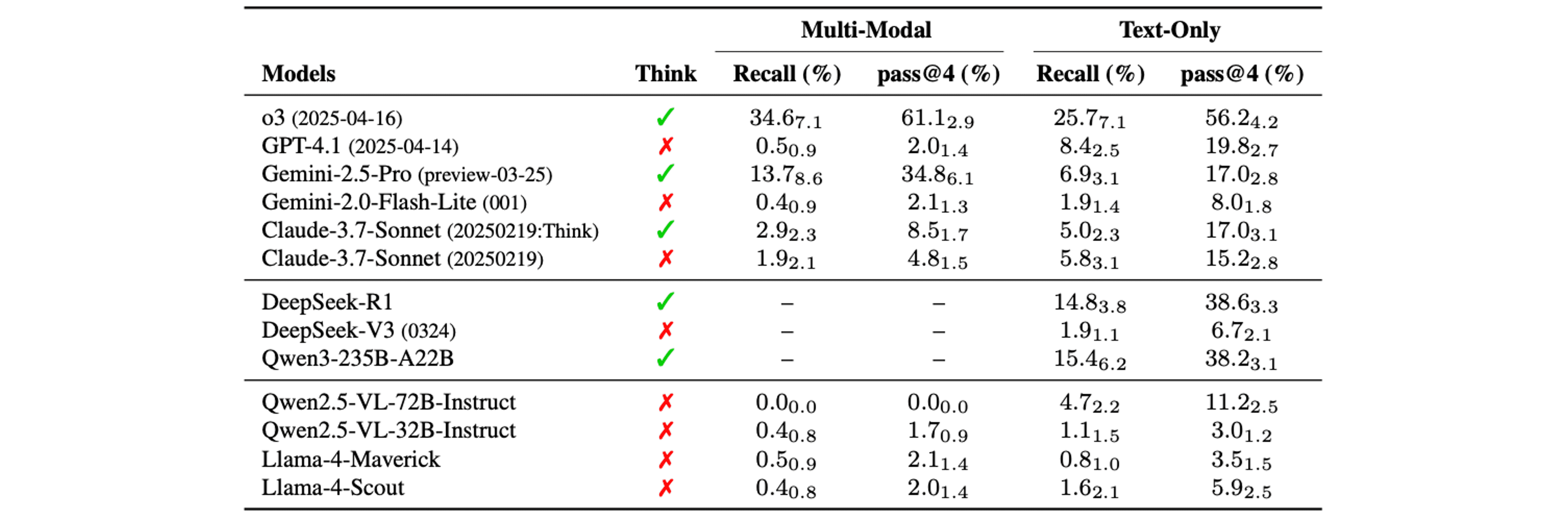
Through SPOT benchmark evaluations on various proprietary and open-source multi-modal models, the following analyses were identified:
High level of difficulty: Open-source models showed near-zero performance in multi-modal environments and struggled with error detection. In text-only environments, they performed slightly better than in multi-modal settings. Similarly, most proprietary models also showed near-zero performance and difficulty in detecting errors, with the exception of o3 and Gemini-2.5-Pro.
Utilization of multi-modal environments by models: Understanding academic papers requires not only text but also images. However, the results show that most models perform better in text-only environments than in multi-modal ones. This suggests that most models are not effectively utilizing image information for error detection. Only o3 and Gemini-2.5-Pro showed lower performance in text-only environments compared to multi-modal ones, indicating that they are appropriately referencing image information.

Additionally, when examining the confidence and pass@4 performance of each model, we can observe some intriguing results. Looking at the graph on the right in the figure above, we see that o3 gets all the answers correct in the Statistical Reporting error category, and the other models also show fairly high accuracy. However, since the confidence scores of all models do not exceed 0.5, this suggests that rather than detecting the errors with certainty, the models are more likely guessing correctly.
Conclusion
LLMs are now demonstrating strong performance not only in the field of computer science but also across various scientific domains. As a result, their role is becoming increasingly important not only as AI Co-Scientists that formulate hypotheses and conduct experiments but also as agents that verify the integrity of scientific research. In the paper titled "When AI Co-Scientists Fail: SPOT—a Benchmark for Automated Verification of Scientific Research," published by the OneLine AI research team, the SPOT benchmark was used to analyze the potential of different language models as verifiers.
The experimental results show that unless models are high-performing ones like o3 or Gemini 2.5 Pro, it is difficult to properly utilize multi-modal data. Even these advanced models produce verification outcomes with such low confidence that they cannot be considered reliable. These findings suggest that current language models still have many shortcomings in their role as AI Co-Scientists. It is hoped that further active research will be conducted based on the SPOT benchmark and its published experimental results to enable AI Co-Scientists to serve as trustworthy verifiers.
References
📝 Paper: https://arxiv.org/abs/2505.11855
🤗 Dataset: https://huggingface.co/datasets/amphora/SPOT-MetaData
🖥️ GitHub: https://github.com/guijinSON/SPOT
