금융 도메인 언어모델 학습을 위한 합성데이터 생성 기법 Part1: Self-Instruct
Date
Sep 16, 2024
Category
LLM-Data

이 글은 ‘Self-Instruct: Aligning Language Models with Self-Generated Instructions(2023)’ 논문을 기반으로 언어모델 학습을 위한 합성데이터 생성 기법을 설명하고 있습니다.
해당 기법으로 원라인에이아이가 생성한 데이터들은 허깅페이스 HAE-RAE Hub에서 확인하실 수 있습니다.
특정 도메인 학습데이터는 원라인에이아이 AI팀에게 문의주시기 바랍니다.
금융 AI 모델 개발의 초석, 데이터
금융 분야에서 AI의 중요성은 날로 커지고 있습니다. 주식 시장 예측, 신용 평가, 사기 탐지 등 다양한 영역에서 AI는 이미 핵심적인 역할을 하고 있지만, AI 모델을 개발하는 과정에서 많은 기업들이 ‘데이터’ 라는 공통된 난관에 부딪힙니다.
예를 들어, 새로운 유형의 금융 사기를 탐지하는 AI를 개발한다고 가정해봅시다. 이를 위해서는 다양한 사기 패턴과 정상 거래 데이터가 필요합니다. 하지만 실제 사기 데이터는 희소하고, 개인정보 보호 문제로 인해 접근이 제한적입니다. 또한 새로운 유형의 사기라면 그에 대한 데이터는 아예 존재하지 않을 수도 있습니다. 이런 상황에서 어떻게 효과적인 AI 모델을 개발할 수 있을까요?
바로 여기서 synthetic data, 즉 '합성 데이터'의 중요성이 대두됩니다. 합성 데이터란 실제 데이터의 특성을 모방하여 인공적으로 생성한 데이터를 말합니다. 이는 단순히 무작위로 만들어낸 가짜 데이터가 아니라 실제 데이터의 복잡한 패턴과 관계를 학습한 AI 모델이 생성한, 실제와 매우 유사하지만 완전히 새로운 데이터입니다.
합성 데이터는 다음과 같은 장점을 가지며 ‘데이터 부족’ 문제에 대한 해결책으로 떠오르고 있습니다:
데이터 부족 문제 해결: 희소한 케이스나 새로운 시나리오에 대한 데이터를 대량으로 생성할 수 있습니다.
개인정보 보호: 실제 고객 데이터를 사용하지 않기 때문에 개인정보 문제에서 자유롭습니다.
다양성 확보: 다양한 조건과 시나리오를 반영한 데이터를 생성할 수 있어, 모델의 일반화 능력을 향상시킬 수 있습니다.
비용 절감: 실제 데이터 수집에 드는 시간과 비용을 크게 줄일 수 있습니다.
금융 도메인 언어 모델 학습을 위한 합성데이터 생성 기법
본 시리즈는 금융 분야에서 활용할 수 있는 인공지능 언어 모델의 학습을 유명 합성데이터 생성 기법을 다룰 예정입니다. 합성데이터 생성 기술 3가지를 살펴보면서 합성데이터의 중요성, 다양한 생성 기법, 그리고 이를 통한 언어 모델의 학습 효과 등을 세부적으로 탐구할 것입니다. 각 포스팅은 이론적 배경부터 실제 적용 사례까지 폭넓게 다루어, 본 시리즈를 통해 금융 분야의 AI 전문가들과 관심 있는 독자들에게 유용한 인사이트를 전달하고자 합니다.
Timeline
SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions (현 포스팅)
WizardLM: Empowering Large Language Models to Follow Complex Instructions (Link)
Cosmopedia: how to create large-scale synthetic data for pre-training (Link)
SELF-INSTRUCT
첫 시작으로 2023년 3월, 세상을 뜨겁게 달군 Stanford의 Alpaca 학습 데이터 생성 방법으로 널리 알려진 "SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions"에 대해서 알아보겠습니다.
이 논문의 핵심 아이디어는 대규모 언어 모델(LLM)을 사용하여 스스로 지시사항(instruction)과 그에 따른 입출력 예시를 생성하게 하는 것입니다. 이 과정을 통해 다양한 태스크에 대한 대규모 데이터셋을 사람의 노력없이 자동으로 생성할 수 있게 됩니다.
Self-Instruct의 전반적인 프로세스는 다음과 같습니다:
사람이 작성한 (instruction, instance) 쌍으로 이루어져 있는 175개 가량의 소수 seed task로 시작합니다.
LLM이 seed task를 in-context example로 하여 새로운 instruction 및 instance를 생성합니다.
생성된 데이터의 품질 및 중복 제거 등의 후처리를 진행합니다.
이 과정을 반복하여 대규모 데이터셋을 구축합니다.
이러한 프로세스로 GPT3를 사용한 실험에서, 생성된 데이터로 파인튜닝한 모델은 기존 GPT3보다 instruction-following 능력이 33% 향상되었습니다. 또한 전문가가 작성한 새로운 태스크에 대해서도 우수한 성능을 보였습니다.
[SELF-INSTRUCT: AI가 스스로 학습하는 혁신적 방법론]
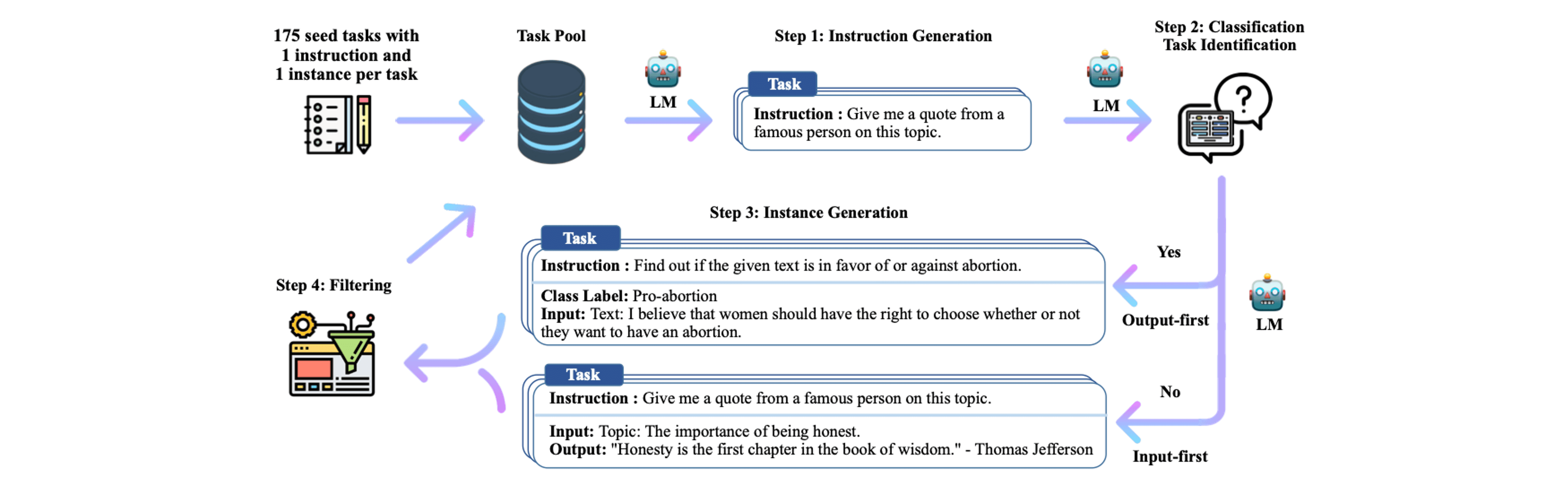
Self-Instruct 방법론의 핵심은 대규모 언어 모델(LLM)을 활용하여 자체적으로 instruction(지시사항)과 그에 따른 instance(입출력 예시)를 생성하는 것입니다. 이 과정을 통해 다양한 태스크에 대한 대규모 데이터셋을 자동으로 구축할 수 있습니다. 앞서 살펴본 Self-Instruct의 전반적인 프로세스에 대해 자세하게 알아보겠습니다.
Step 0. Seed Task 설정
연구팀이 직접 작성한 175개의 task(instruction + instance)를 seed task로 설정하였습니다. 이 초기 task들은 다양한 NLP 작업을 포함하며, 향후 추가적으로 생성될 instruction 세트에 대한 지침이 되어줍니다.
Step 1. Instruction 생성
instruction 생성을 위해 LLM(GPT3 사용)에게 8개의 task instruction을 in-context 예시로 제시합니다. 이 중 6개는 연구팀이 작성한 task, 2개는 이전 단계에서 모델이 생성한 task에서 가져옴으로써 다양성 증진과 함께 instruction을 생성합니다.
Step 2. 분류 Task 식별
생성된 지시사항의 분류 task 여부를 확인합니다. 이는 분류 task 여부에 따라 instance 생성 방식을 결정하기 때문에 중요합니다. 분류 task 판별을 위해 seed task에 존재하는 12개의 classification instruction과 19개의 non-classification instruction을 활용한 few-shot 방식으로 확인합니다.
Step 3. Instance Generation
앞선 과정을 통해 생성된 instruction과 task 유형이 주어지면 instruction-input-output 예시를 in-context 예시로 제공해줌으로써 instruction에 대한 instance를 독립적으로 생성합니다. 이때 분류 task 여부에 따라 다음과 같이 두 가지 접근 방법으로 나뉘게 됩니다.
Input-first Approach: 분류 task가 아닌 task. LLM에게 instruction을 입력으로 주고, 이에 해당하는 output을 출력하도록 만듭니다. 이때 다른 task에 대한 예시를 in-context 예시로 활용합니다.
Output-first Approach: 분류 task. 주어진 instruction에 대해 가능한 클래스 레이블을 먼저 생성하고, 각 클래스 레이블에 맞춰서 적절한 input을 생성합니다.
Step 4. 필터링 및 후처리
생성된 데이터의 품질을 보장하기 위해 다음과 같은 여러 필터링 단계를 거칩니다:
유사도 검사: 새로 생성된 지시사항이 기존 지시사항과 ROUGE-L 유사도가 0.7 미만인 경우에만 추가합니다.
키워드 필터링: 'image', 'picture', 'graph' 등 LLM이 처리할 수 없는 키워드가 포함된 지시사항을 제외합니다.
중복 제거: 완전히 동일하거나 같은 입력에 다른 출력을 가진 인스턴스를 필터링합니다.
휴리스틱 기반 필터링: 지시사항이 너무 길거나 짧은 경우, 출력이 입력의 단순 반복인 경우 등을 제거합니다.
Step 5. 반복
Step 1 ~ 4를 반복하여 최종적으로 52,000개 이상의 instruction과 82,000개 이상의 instance를 생성하였습니다.
[SELF-INSTRUCT DATASET: 다양성 및 퀄리티 높은 데이터셋]
Statistics
Self-Instruct를 통해 생성된 데이터셋에 대한 통계는 다음의 표와 같습니다. 약 52,000개의 instruction과 82,000개의 instruction으로 구성되어 있습니다.

Diversity
생성된 데이터셋의 다양성을 확인하기 위해 Berkely Neural Parser를 사용한 동사-명사 구조를 확인하였고, ROUGE-L 점수 오버랩을 통해 데이터 간의 중복도를 확인하였습니다.
동사-명사 구조 확인
다음과 같이 다양한 instruction format을 보여주면서 데이터셋의 다양성을 확인할 수 있습니다.

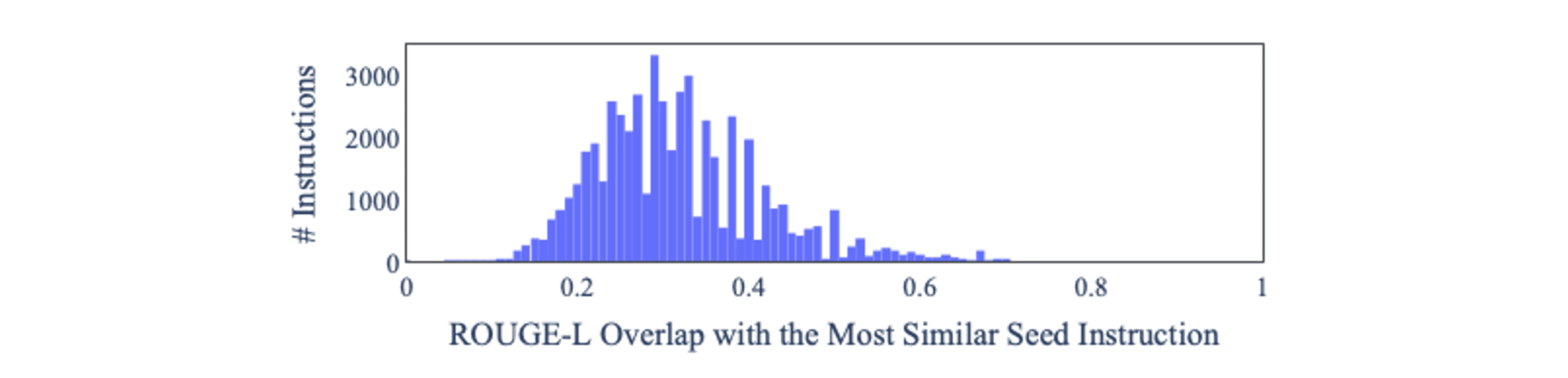
ROUGE-L 점수 오버랩
ROUGE-L 오버랩이 그리 높지 않은 것으로 보아 instruction의 중복도가 낮다는 것을 확인할 수 있습니다.
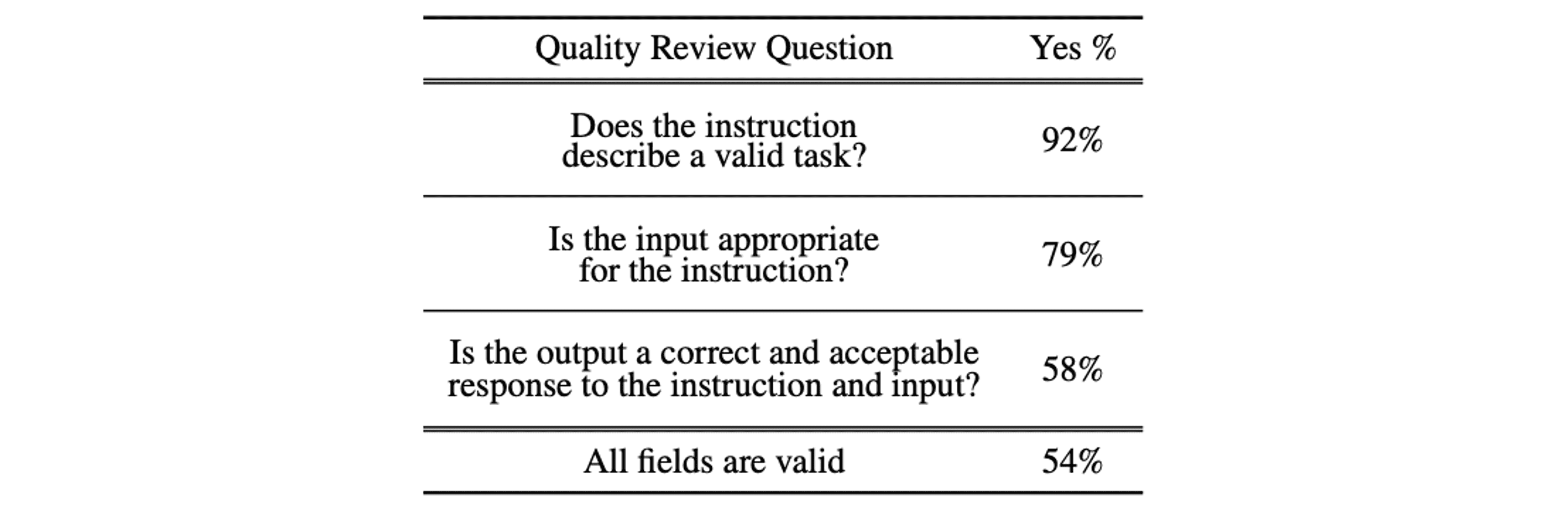
Quality
생성된 데이터셋의 퀄리티 확인을 위해 200개의 instruction 및 instance 쌍을 랜덤하게 샘플링하여 전문가에게 instruction과 instance가 알맞은지 물어보는 방식으로 평가를 진행하였습니다. 그 결과 대부분의 instruction이 유의미하였으나, instance의 경우에 약간의 노이즈를 포함하고 있었습니다.
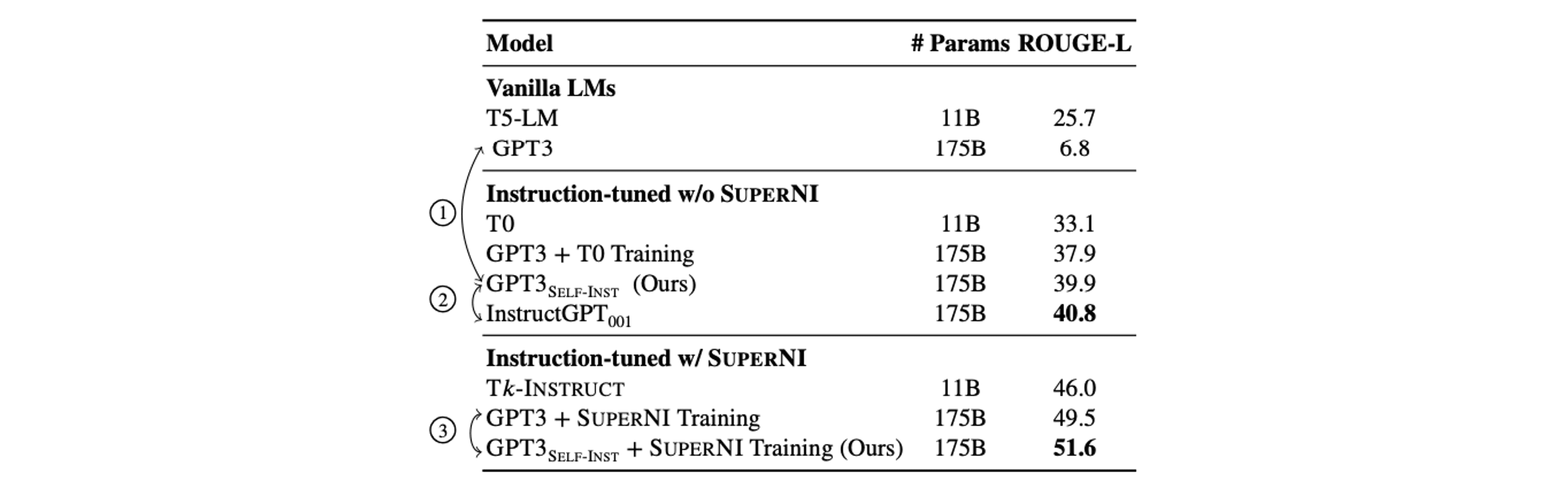
[SELF-INSTRUCT EXPERIMENTS]
Self-Instruct로 생성된 데이터셋을 활용한 모델 학습 관련 실험 결과는 다음과 같습니다.
SUPERNI 벤치마크 테스트: SELF-INSTRUCT로 파인튜닝된 GPT3(GPT3SELF-INST)는 기존 오리지널 GPT3보다 33% 더 높은 성능을 보였습니다. 이는 인간이 주석을 단 데이터로 훈련된 InstructGPT001과 거의 대등한 수준입니다.
새로운 태스크에 대한 일반화 능력: 연구팀은 252개의 새로운 사용자 지향 지시사항을 만들어 평가했습니다. GPT3_SELF-INST는 이 테스트에서도 우수한 성능을 보였으며, 공개된 다른 지시 데이터셋으로 훈련된 모델들을 크게 앞섰습니다.

데이터 크기 및 품질의 중요성: 더 많은 생성 데이터로 훈련할수록 모델의 성능이 향상되었지만, 약 16,000개의 지시사항 이후로는 성능 향상이 둔화되었습니다. 또한 연구팀은 InstructGPT003을 사용하여 생성된 데이터의 품질을 개선하는 실험도 진행했습니다. 이렇게 개선된 데이터로 훈련한 모델은 원본 데이터로 훈련한 모델보다 10% 더 높은 성능을 보였습니다.

SELF-INSTRUCT Conclusion
SELF-INSTRUCT는 인간의 노력을 최소화하면서 LLM을 활용하여 효율적으로 대규모의 다양한 instruction 데이터를 생성할 수 있는 방법을 제시하였습니다. 이를 통해 다양한 task에 대해 instruction 데이터셋을 제작하고, 이 데이터셋으로 모델을 학습하여 해당 task에 대한 모델의 instruction-following 능력을 크게 개선시켰습니다.
SELF-INSTRUCT는 다음과 같은 방법으로 금융 도메인에 적용될 수 있습니다:
금융 특화 지시사항 생성: 금융 도메인의 전문 지식을 바탕으로 초기 시드 태스크를 신중히 선별합니다. 예를 들어, "주어진 재무제표를 분석하여 회사의 유동성 비율을 계산하라" 또는 "특정 주식의 과거 데이터를 바탕으로 향후 주가 동향을 예측하라" 등의 태스크를 포함할 수 있습니다.
금융 특화 언어모델 활용: 일반적인 LLM 대신 금융 도메인 텍스트로 사전학습된 언어모델을 사용하여 더욱 정확하고 전문적인 데이터를 생성합니다.
금융 규제 및 컴플라이언스 반영: 데이터 생성 과정에서 금융 규제와 컴플라이언스 요구사항을 반영합니다. 예를 들어, 자금세탁방지(AML) 관련 시나리오를 다양하게 생성할 수 있습니다.
시장 변동성 시뮬레이션: 다양한 시장 상황(강세장, 약세장, 변동성 높은 시기 등)을 반영한 데이터를 생성하여 모델의 robustness를 향상시킵니다.
새로운 금융 상품 시나리오: 아직 시장에 출시되지 않은 새로운 금융 상품에 대한 가상의 데이터를 생성하여, 미래 시나리오에 대비할 수 있습니다.
이러한 방식은 기존에 희소했던 유형의 데이터를 손쉽게 생성함으로써 이점을 얻을 수 있습니다. 예를 들어, 신용평가 모델 개발 시 다양한 재무 상황과 신용 이력을 가진 가상의 고객 프로필을 대량으로 생성하여 모델은 희소한 케이스에 대해서도 학습할 수 있게 되어, 더욱 공정하고 정확한 신용평가가 가능해집니다. 이를 포함해 다양한 도메인에서 합성 데이터를 생성함으로써 모델을 다양한 관점에서 학습시킬 수 있고, 이는 금융 AI 모델에 큰 발전을 가져다 줄 것입니다.
결론적으로, SELF-INSTRUCT와 같은 혁신적인 방법론을 금융 도메인에 적용함으로써, 데이터 부족 문제를 극복하고 더욱 강력하고 유연한 AI 모델을 개발할 수 있습니다. 이는 단순히 기술적 진보를 넘어, 더 정확한 리스크 관리, 개인화된 금융 서비스, 효율적인 자산 관리 등을 통해 금융 산업 전반에 긍정적인 효과를 가져올 수 있습니다.
