한국어 추론 언어 모델 Ko-R1-3 개발기 #2
Date
Jul 24, 2025
Category
Research
Ko-R1-3 개발의 두 번째 챕터
지난 Ko-R1-3 첫 번째 개발기를 통해서 모델 학습의 다양한 부분에 대해서 살펴보았습니다. 그 사이 저희 팀은 KISTI, ORACLE과 협력하여 H200 2대, H100 2대 노드에서 약 50개의 학습 작업을 진행하며, 단 일주일 만에 2,000 H200-hour이 넘는 리소스를 사용하며 대규모 실험을 진행했습니다.
현재 저희는 한국어 Post-training을 위해 1,000만 개가 넘는 샘플을 수집했지만, 이 데이터 전체를 5 epoch 학습시키는 것은 이미 사용한 수천 시간을 훌쩍 넘는, 예산을 초과하는 일이기에 '최적의 Post-training 데이터 조합'을 찾는 것, 어떤 데이터를 남기고, 어떤 데이터를 버릴지, 그리고 어떤 데이터의 비중을 높여야 최고의 성능을 낼 수 있을지 결정해야 했습니다. 지금부터 저희가 이 과정에서 얻은 교훈들에 대해서 소개하겠습니다.
데이터셋 구성
실험과 모델 학습에 사용된 데이터셋은 다음과 같이 총 7개의 카테고리로 구성되어 있습니다:
OpenThought3: gemini-2.5-flash-lite-preview-06-17을 활용하여 OpenThought3 프롬프트를 한국어로 번역하고, 번역 과정에서 길이가 지나치게 바뀌는 샘플은 필터링을 진행하였습니다.
rStar-Coder: OpenThought3와 똑같은 번역 및 필터링 과정을 rStar-Coder 데이터셋에 적용하여 데이터셋을 확보하였습니다.
Web-Daily/Code/Science/Medical: 웹으로부터 수집해서 데이터 유형에 따라 태깅이 되어 있는 한국어 instruction 데이터셋. 이때 이미지가 포함되어 있거나 이유없이 길거나 짧은 데이터 샘플을 제거하였습니다. Web-Daily 데이터는 노이즈가 섞인 데이터 혹은 안전하지 않은 프롬프트가 포함되어 있는 반면, Code, Science, Medical 데이터는 더욱 깔끔하게 정리되어 있거나 domain-specific한 전문 용어로 작성되어 있는 데이터로 구성되어 있습니다.
MCQA-Augmented: KMMLU-Train 서브셋에서 시작해서 ‘정답: N’ 또는 ‘\boxed{N}’과 같이 다양한 응답 스타일로 증강된 데이터가 포함되어 있습니다. 뿐만 아니라 BM25를 통해 검색된 유사한 질문을 활용하여 더욱 다양한 포맷의 MCQA 데이터로 증강하였습니다.
데이터셋 제작 및 증강 과정에는 모두 Qwen3-32B가 사용되었고, 전체 프로세스에는 대약 4,000 H100 hours기 소요되었습니다. (심지어 아직도 생성중입니다 🤭)
평가 세팅
모델의 벤치마크 오버피팅을 방지하기 위해 현존하는 한국어 벤치마크를 다음과 같이 validation set과 test set으로 구분하여 평가하였습니다:
Category | Validation | Test |
|---|---|---|
General | KMMLU-Redux | KMMLU-Pro, GPQA |
Reasoning | MCLM-Ko | HRM8K, LiveCodeBench |
Korean Knowledge | HAE-RAE Bench | CLicK, KoBALT |
Medical | ClinicalQA |
평가 하이퍼파라미터:
temperature=0.7,top_p=0.9,max_tokens=32768
학습 결과
Ablation #1: 카테고리 별 성능
첫 번째로 각 데이터셋(OpenThought3, 4개의 웹 데이터, MCQA-Augmented)이 모델의 성능에 미치는 영향을 분석하였습니다. 이때, 모델의 종류에 따른 편향이 발생하지 않도록 Kanana-1.5-8B-Instruct와 Gemma3-4B-Instruct, 두 모델을 활용하여 실험을 진행하였습니다. 또한 모델이 MCQA 포맷에서도 잘 작동할 수 있도록 최소한의 MCQA 데이터를 모델 학습 데이터에 포함시켰습니다.
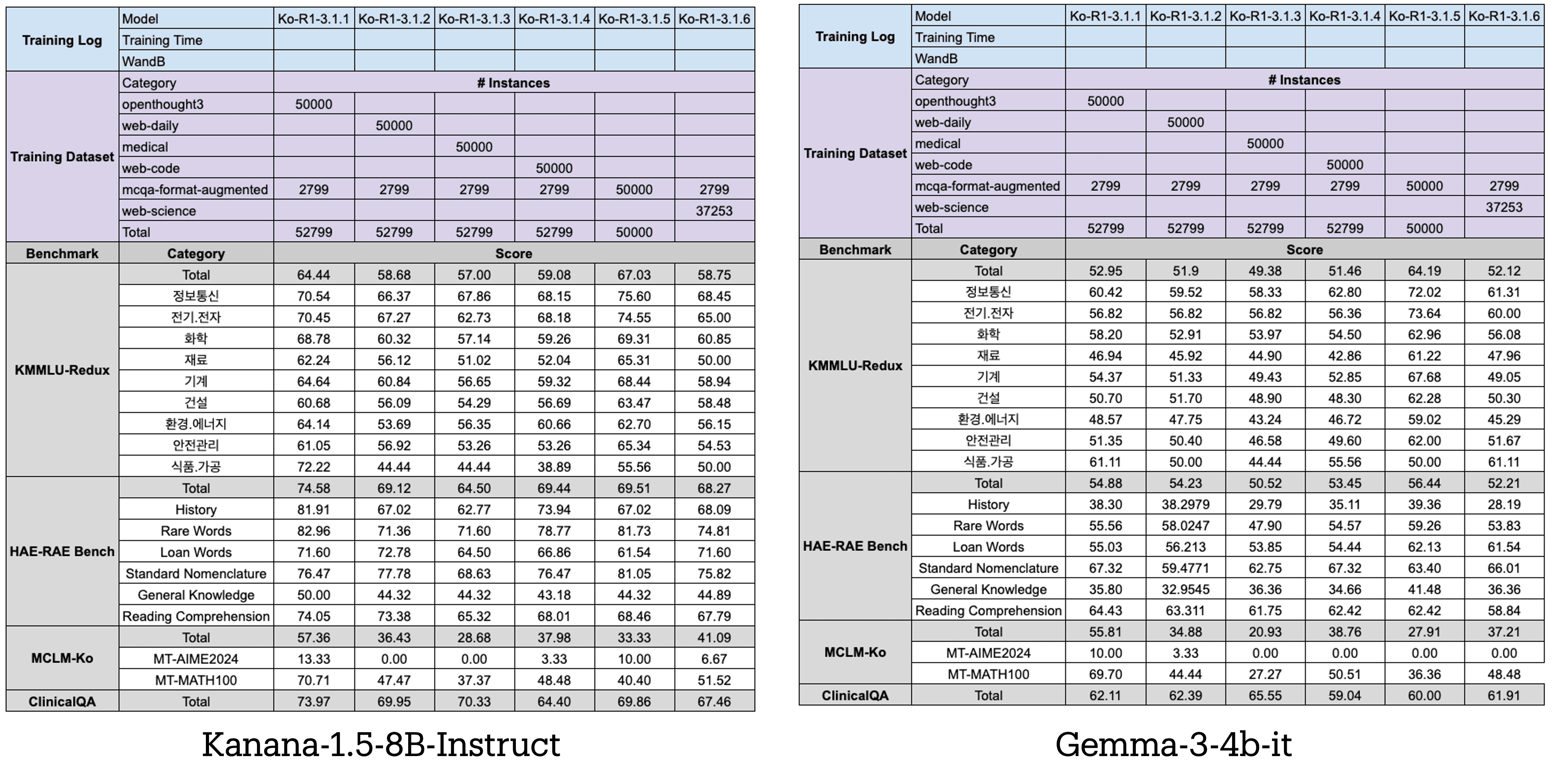
결과를 보면 OpenThought3 데이터가 지식 기반 벤치마크인 HAE-RAE Bench를 포함해서 모든 벤치마크에서 성능 향상을 보여주며 베이스 모델이 모델 자신의 parametric knowledge를 완전히 활용하지 못한다는 것을 보여줍니다. 그 뒤로는 MCQA-Augmented, Web-Science, Web-Code 순으로 큰 성능 향상을 보여줍니다. 하지만 예상과 다르게 Web-Medical 데이터를 사용한다고 ClinicalQA 점수에는 큰 영향이 없었기에 후속 실험으로는 Web-Medical 데이터셋의 크기를 100k로 늘려서 scaling이 hidden value를 해금할 수 있는지를 확인하였습니다.
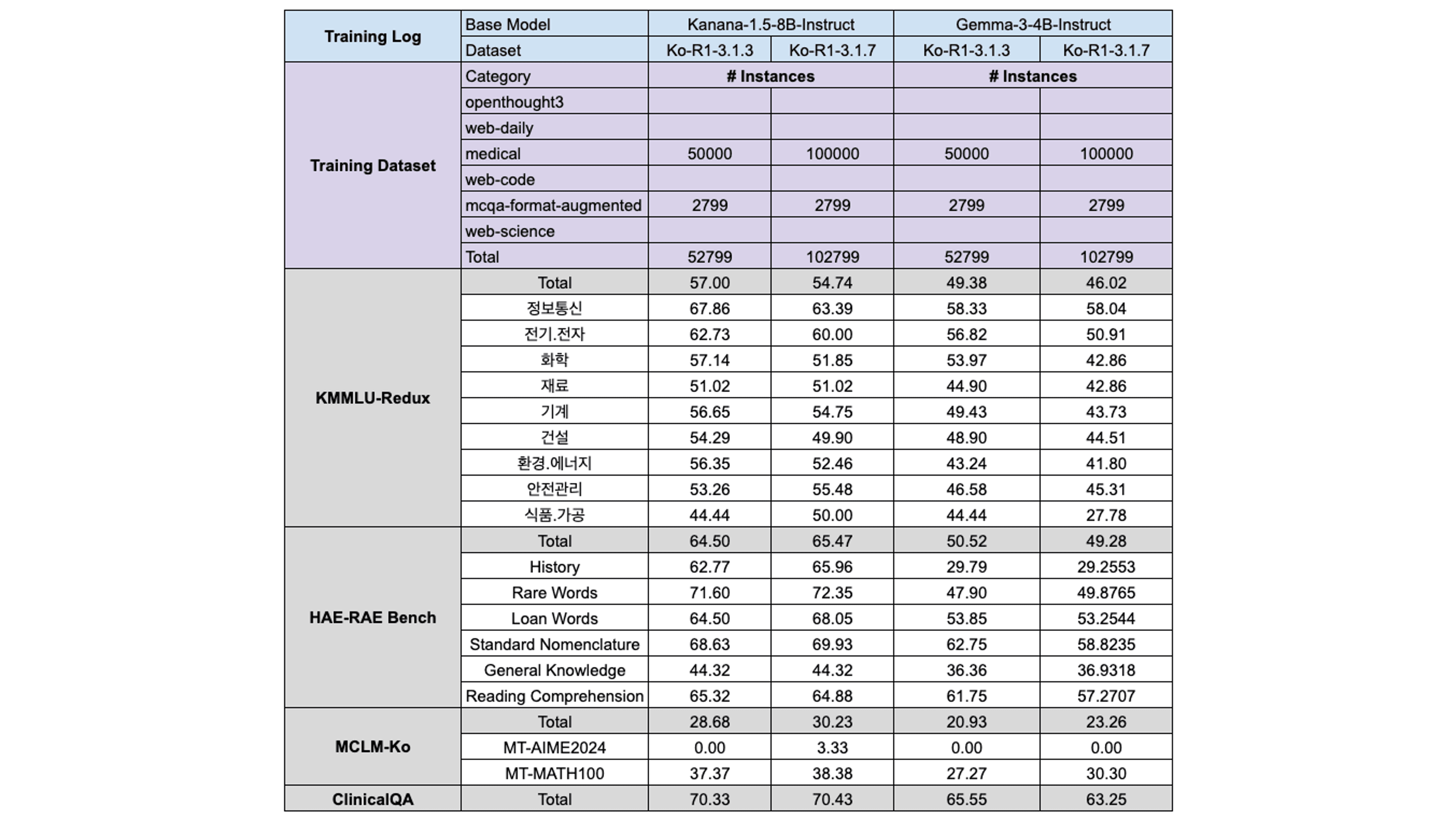
Web-Medical 데이터를 scaling 했을 때, 두 모델 모두에서 별 효과가 없거나 오히려 성능이 떨어지는 문제들이 발생하기도 했습니다. 따라서 최종 학습에서는 해당 데이터를 완전히 제거하기로 결정하였습니다.
Ablation #2: 카테고리 교차 효과
데이터는 혼자일 때 뿐만 아니라 서로 혼합되어 사용될 때, 추가적인 성능 향상을 가져다 주기도 합니다. 이러한 점을 고려하여 수집한 데이터에 대해서도 데이터 혼합의 효과를 분석해보았습니다.
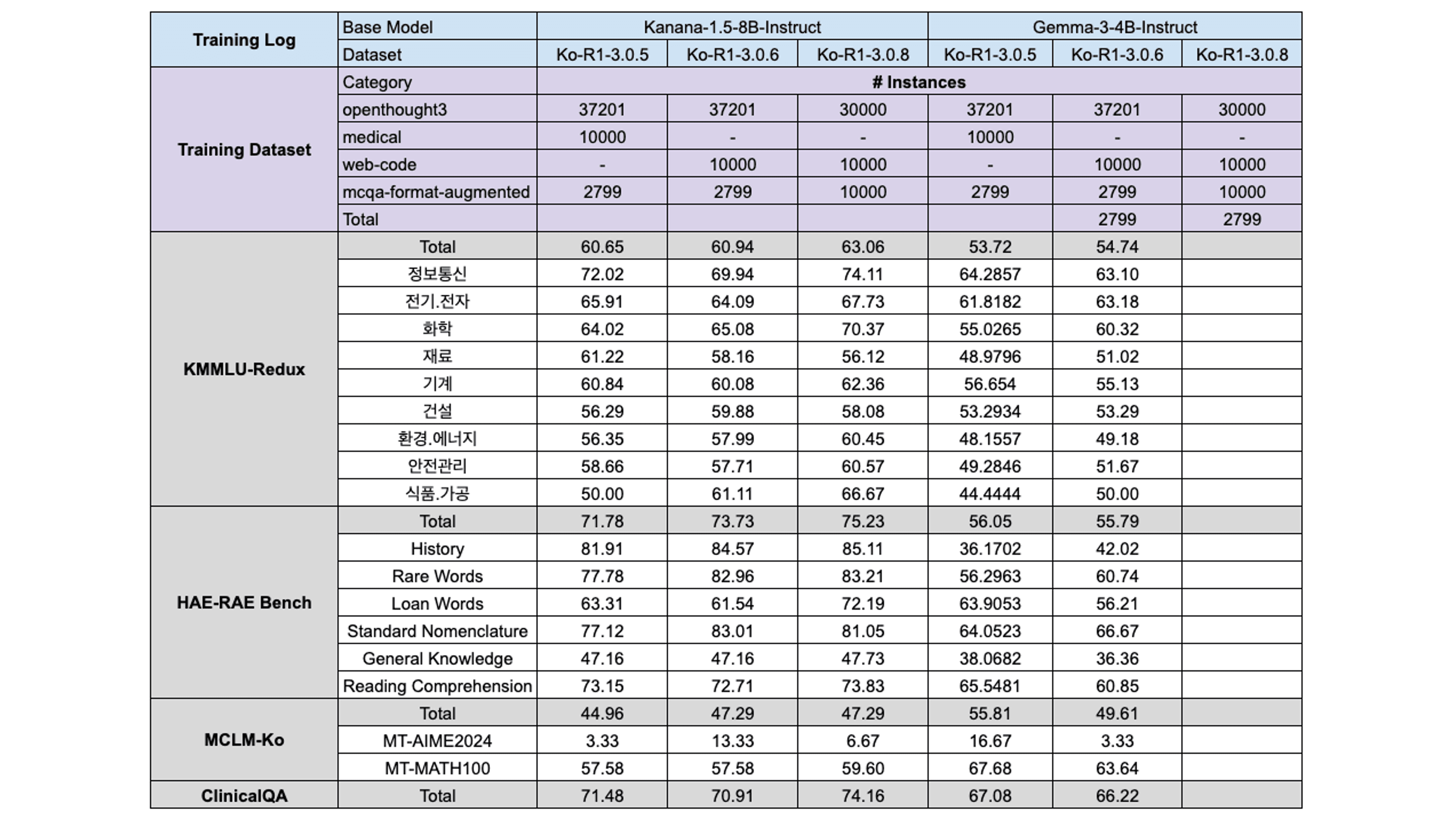
Kanana 모델의 Ko-R1-3.0.5와 3.0.6 모델을 보면 앞선 Web-Medical 데이터의 불필요성을 다시 한 번 확인시켜줍니다. 해당 학습 세팅에서는 Web-Medical 데이터를 Web-Code로 교체한 결과, HAE-RAE Bench와 MCLM에서 보다 큰 성능 향상을 보여주었기 때문입니다. 또한 Web-Code 데이터는 MCLM 벤치마크와 시너지 효과를 보여주는 것을 확인하고, 좋은 품질의 코드 데이터셋인 rStar-Coder 데이터를 번역하여 데이터셋에 포함시키기로 결정했습니다. (하지만 Gemma는 코드 데이터로부터 큰 이점을 얻지는 못 했습니다.)
Ablation #3: 증강하느냐, 하지 않느냐, 그것이 문제로다
다음으로 KMMLU-Train 세트를 어디까지 증강시킬 수 있는가를 분석하였습니다. 이 과정에서 BM25를 활용하여 비슷한 질문의 answer choice를 꼬아부텨 option의 개수를 늘려 다양성을 부여하였습니다.
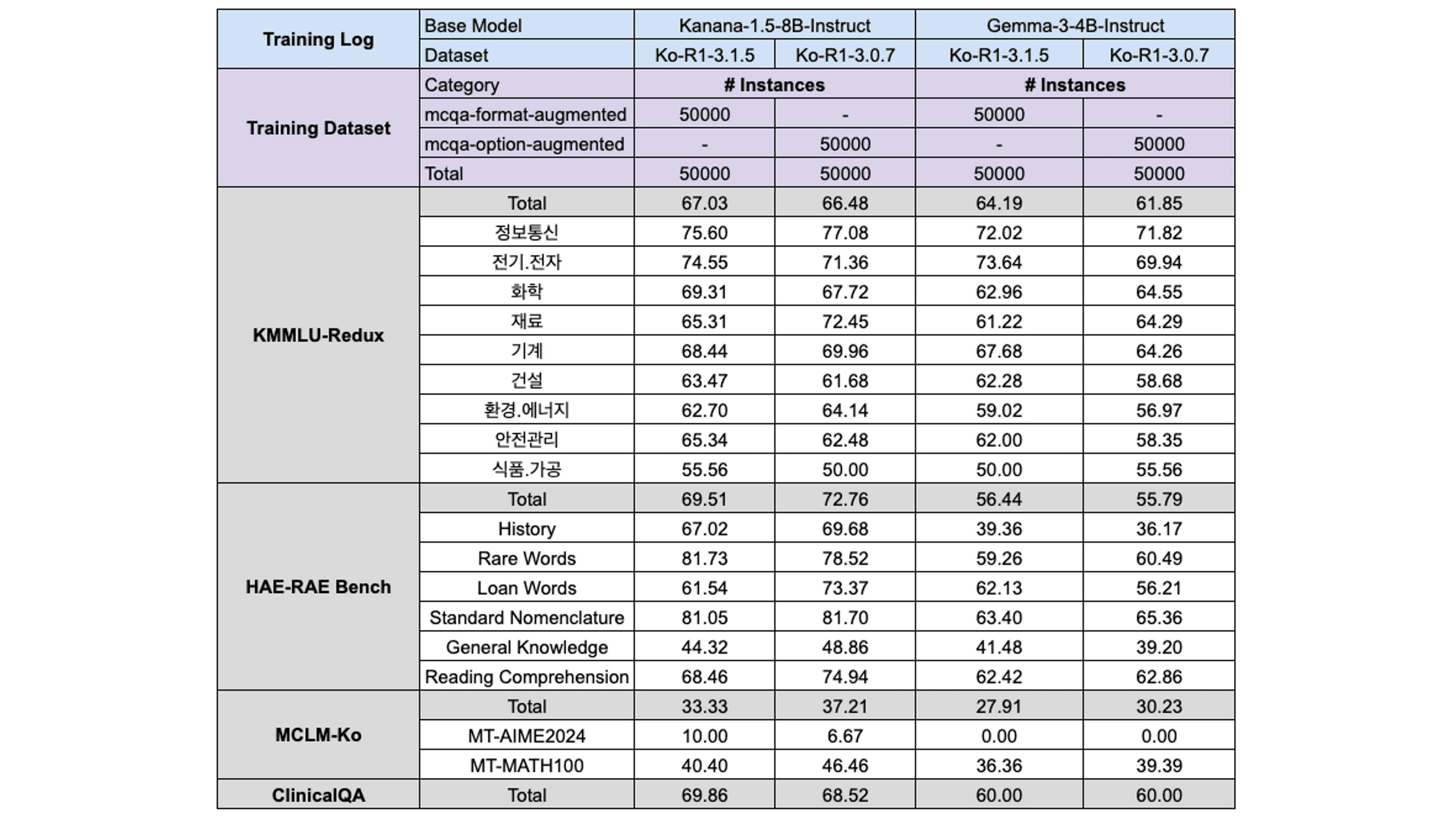
하지만 증강 결과 데이터로부터 모델을 학습한 결과 대부분의 MCQA 벤치마크에서 오히려 역효과가 발생하였습니다. 이러한 결과가 나오게 된 이유는 다음의 2가지로 유추해볼 수 있습니다:
BM25 기반 정답 선택지 증강이 모델 학습에 노이즈 요소로 작용
평가 벤치마크가 주로 4개의 선택지로 이루어져 있기에 정답 선택지를 증강하는 것이 역효과를 가져옴
따라서 최종 학습에는 증강된 MCQA 데이터셋을 소수만 포함하여 다양성 유지 역할로 활용하였습니다.
Ablation #4: 한국어-영어 믹스
최종 모델 학습에는 데이터의 수를 늘리기 위해 영어 데이터도 함께 포함하고자 합니다. 이때 한국어 성능 저하 없이 영어 데이터를 활용하기 위해 다음과 같이 데이터 비율을 설정하고 실험을 진행하였습니다: 1:1 / 1:4 (ko:en)
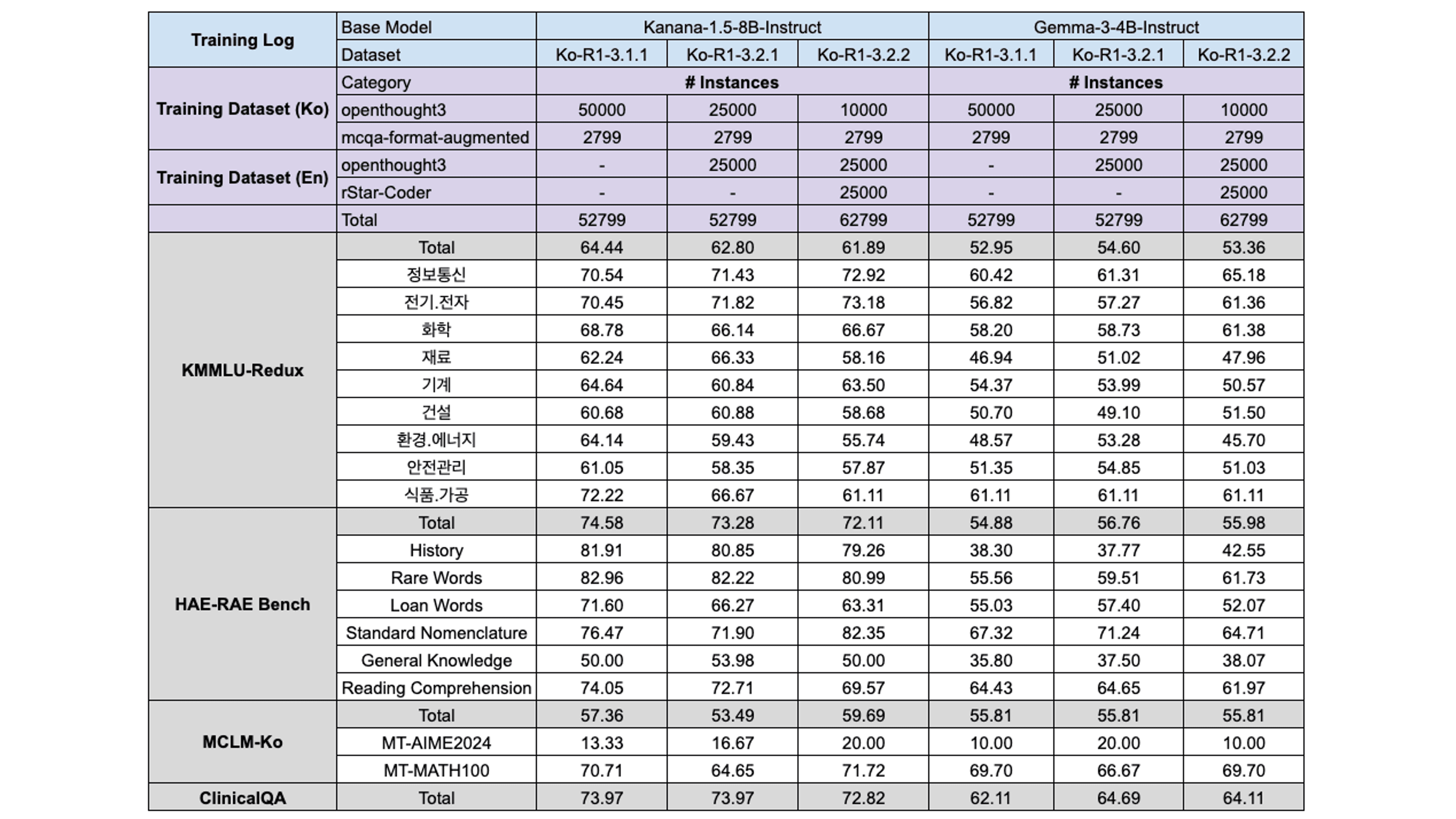
Kanana 모델의 경우, 이전 실험들과 비슷하게 영어 데이터를 추가하면 KMMLU-Redux와 HAE-RAE Bench의 성능은 떨어지고, rStar-Coder 데이터를 추가하니 수학 능력이 향상되었습니다. 반면에 Gemma는 큰 손실없이 영어 데이터 혼합을 받아내는 것을 확인할 수 있습니다. 이러한 차이는 Kanana가 방대한 한국어 추론 데이터에 영향을 받지만, Gemma는 아무런 페널티 없이 영어 데이터를 흡수할 수 있다는 것을 시사합니다.
추가 분석
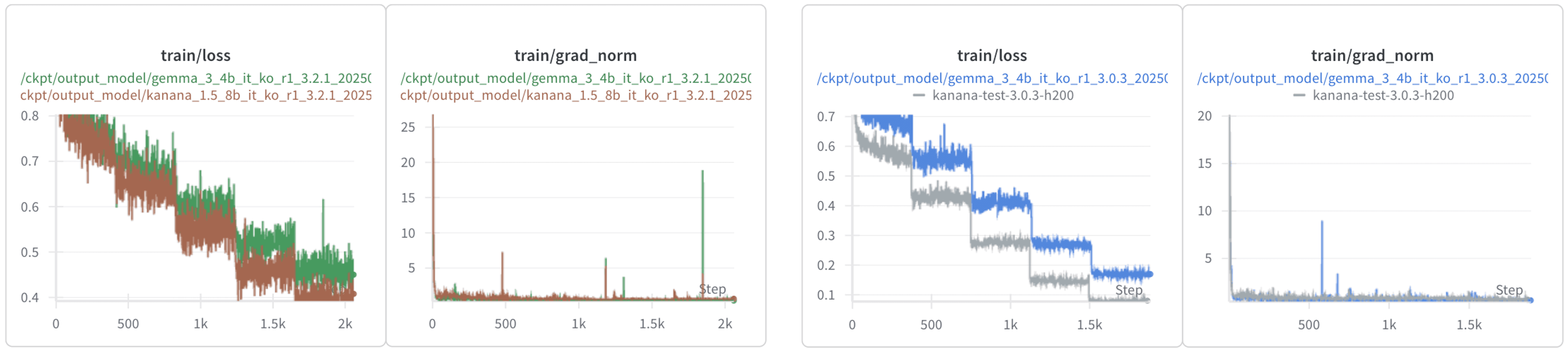
1. Loss Spikes & Grad-norm
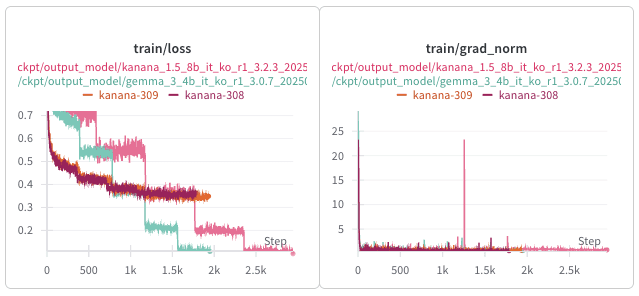
동일한 데이터에서 학습했음에도 불구하고, Gemma는 샤프한 grad-norm 변동성을 보여주고, 가끔씩 loss spike가 발생하였습니다. 하지만 이러한 현상이 최종 체크포인트에는 큰 영향을 주지 않았습니다.
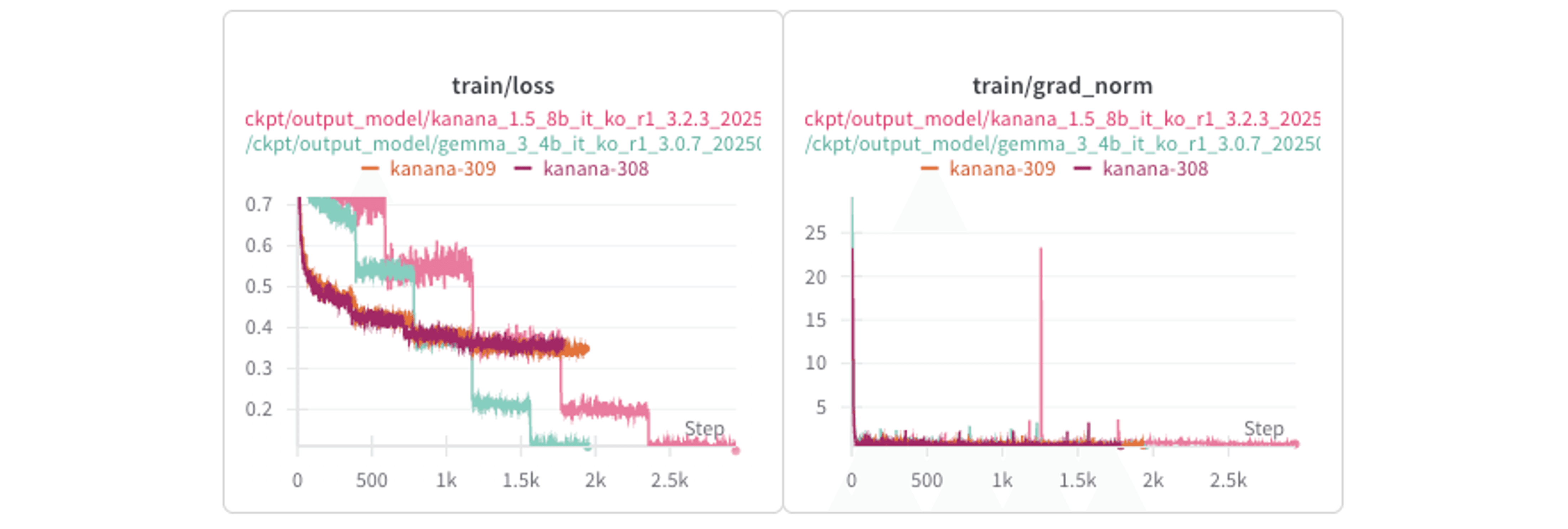
2. Loss Curves
gradient checkpointing 혹은 FSDP를 사용하지 않은 single-GPU 환경에서는 loss curve가 좀 더 작은 변동폭을 보여줬습니다. 반면에 multi-GPU 환경에서는 매 에폭마다 계단식에 가까운 loss drop을 보여줬습니다. 하지만 이러한 현상도 모델의 최종 성능에는 큰 영향을 주진 않았습니다.
References
📝 Original Post - Link
